Lenssterkte berekening bij cataract
Uitgangsvraag
Welke formule(s) voor het berekenen van de lenssterkte heeft/hebben de voorkeur door de komst van nieuwe lensformules?
Aanbeveling
Gebruik bij de gemiddelde ooglengtes (22 tot 26 mm) één van de gangbare lensformules voorafgaand aan cataractchirurgie.
Gebruik bij korte en lange ogen één van de gangbare lensformules voorafgaand aan cataractchirurgie.
Informeer patiënten met korte ogen (< 22 mm) en patiënten met lange ogen (> 26 mm) dat het risico op restafwijking groter is.
Overwegingen
Voor alle groepen ogen geldt dat de gemiddelde prediction error van alle lenssterkteformules afwijkt van nul. Voor een oog van gemiddelde lengte (22 tot 26 mm) lijkt dit het laagst. Voor een oog met een lange ooglengte (> 26 mm) lijkt dit wat hoger en voor een korte ooglengte (< 22 mm) het hoogst. Omdat in deze module niet specifiek gekeken is naar afwijkingen in de prediction error tussen verschillende aslengtes, kan hier niet specifiek een afweging voor gemaakt worden.
Voor- en nadelen van de interventie en de kwaliteit van het bewijs
Op basis van de beschikbare literatuur is er geen duidelijke voorkeur aan het geven welke lenssterkteformule de beste berekening van de gemiddelde prediction error voor korte (< 22 millimeter), gemiddelde (22 tot 26 millimeter) of lange (> 26 millimeter) ogen geeft.
Uit de analyse van de resultaten voor korte ogen blijkt er een statistisch significant verschil te zijn tussen de Haigis en de Hoffer Q (MD= -0,08 (95% BI= -0,15 tot -0,02) en tussen de Haigis en de SRK/T (MD= -0,13 (95% BI= -0,26 tot 0.00). Het verschil dat is gevonden valt echter binnen de waarde van 0,25 Dioptrie die als klinisch (voor de patiënt) relevant verschil wordt beschouwd. De bewijskracht hiervoor is echter laag. Voor de overige vergelijkingen (Haigis versus Holladay 1, Haigis versus Holladay 2, Barrett Universal II versus de SRK/T en Barrett Universal II versus Holladay 2) werden geen verschillen gevonden. De bewijskracht hiervoor is laag. De gemiddelde prediction error is voor de Haigis in elk van de vergelijking het kleinst, waardoor er wellicht een lichte voorkeur kan zijn voor de Haigis ten opzichte van de Hoffer Q, Holladay 1 en Holladay 2. Hierbij dient opgemerkt te worden dat er geen studies zijn gevonden op basis van de gebruikte criteria die de vergelijking hebben onderzocht tussen de Haigis en de Barrett Universal II.
Voor de gemiddelde ogen is het op basis van de beschikbare literatuur eveneens onduidelijk welke lenssterkteformule de voorkeur heeft bij het berekenen van de gemiddelde prediction error voor de gemiddelde ogen. Uit de analyse van de resultaten voor gemiddelde ogen blijkt er een statistisch significant verschil te zijn tussen de Barrett Universal II versus Haigis (MD= -0,07 (95%BI= -0,12 tot -0,02). Het gevonden verschil valt echter binnen de waarde van 0,25 Dioptrie en wordt niet als een (voor de patiënt) klinisch relevant verschil beschouwd. De bewijskracht hiervoor is laag. Voor de overige vergelijkingen Haigis versus SRK/T, Haigis versus Holladay 1, Holladay 2 versus Holladay 1 en Barrett Universal versus SRK/T werden geen verschillen gevonden. Op basis van deze resultaten is er geen duidelijke voorkeur voor een bepaalde lenssterkteformule aan te geven. De bewijskracht is redelijk.
De analyse van de resultaten van de lenssterkteformules voor de lange ogen laten ook geen duidelijke voorkeur voor één van de formules zien. Echter, uit de resultaten komt naar voren dat de gemiddelde prediction error voor de Haigis statistisch significant kleiner blijkt te zijn dan de Holladay 1 (-0,09 (95% BI= -0,17 tot -0,01). Het gevonden verschil valt binnen de waarde van 0,25 Dioptrie en wordt zodoende niet als een (voor de patiënt) klinisch relevant verschil beschouwd. De bewijskracht hiervoor is redelijk. Voor de overige vergelijkingen Haigis versus Barrett Universal II, Haigis versus SRK/T en Holladay 2 versus Holladay 1 werden geen statistisch significante of klinisch relevante verschillen gevonden. De bewijskracht voor de Haigis versus Barrett Universal II is laag en de bewijskracht voor de Haigis versus SRK/T en Holladay 2 versus Holladay 1 is redelijk.
Afwezigheid van een verschil tussen de formules kan mogelijk verklaard worden doordat de resultaten van een aantal studies niet gepoold konden worden met de systematische reviews van Wang (2018a en 2018b). Poolen was niet mogelijk vanwege heterogeniteit in de rapportage van de resultaten en vanwege heterogeniteit in de formulevergelijkingen.
De overall bewijskracht voor het gevonden gemiddelde verschil is laag.
In de huidige analyse is gekeken naar het verschil in Mean Absolute Prediction Error. Omdat absolute waarden in het algemeen een scheve verdeling laten zien, zou het gebruik van de mediaan statistisch zinvoller zijn. Vrijwel alle studies gebruiken echter de gemiddelde waarde om vergelijkingen te doen. Om deze reden is gekozen om dit voor de huidige analyse ook te gebruiken.
De gemiddelde afwijking van de gekozen target zegt iets over de kwaliteit van de lensberekening in een groep patiënten. Een andere parameter die klinisch zinvol is, is het aantal patiënten dat niet binnen 1 D van de beoogde refractie eindigt. Deze getallen hebben wij in de huidige analyse niet berekend. Op basis van klinische ervaring en op basis van een aantal studies die hier wel naar gekeken hebben, lijkt de Barrett Universal II een lager aantal patiënten op te leveren die buiten 1 D van de beoogde refractie eindigen.
Waarden en voorkeuren van patiënten (en eventueel hun verzorgers)
De verwachtingen van patiënten met betrekking tot brilonafhankelijkheid na een cataractoperatie worden groter. Een zo laag mogelijke Prediction Error is om deze reden ook belangrijk. De uitkomsten van de huidige analyse laten zien dat er (klinisch) weinig verschil zit in de uitkomsten van de verschillende moderne lensformules. Er is met name een aanzienlijke spreiding in de refractieve uitkomst na een cataractoperatie ondanks de gebruikte lensformule. Het is belangrijk om de juiste verwachtingen te scheppen voor de operatie.
Kosten (middelenbeslag)
Niet alle commercieel verkrijgbare biometrie-apparatuur beschikt over alle moderne lensformules, zoals de Barrett Universal II formule. Wel kan handmatig de lenssterkte met deze formule worden berekend via de website van de Asia-Pacific Association of Cataract & Refractive Surgeons (APACRS). Er dient dan wel extra te worden gelet op overschrijffouten. Indien één lensformule er beter uit zou springen, zou er geadviseerd kunnen worden een bepaalde biometer aan te schaffen.
Aanvaardbaarheid, haalbaarheid en implementatie
Bij het berekenen van de lenssterkte, dient erop te worden gelet dat de lensconstanten van de lensformules zijn geoptimaliseerd of eventueel gepersonaliseerd. Alleen dan zullen de meest optimale resultaten worden behaald. In de huidige bestudeerde studies waren de lensformules allemaal geoptimaliseerd.
Omdat uit de analyse naar voren komt dat er geen significante verschillen zijn in de Mean Prediction Error tussen de verschillende lensformules, verwachten wij geen problemen bij de implementatie van de huidige aanbevelingen.
Rationale van de aanbeveling: weging van argumenten voor en tegen de interventies
Ondanks verwachtingen dat nieuwe generatie formules een betere voorspellingskracht zouden hebben, bleek dat niet uit de literatuur. Voor de korte, gemiddelde en lange ooglengtes verschillen de gangbare lensformules Barrett Universal II, Haigis, Hoffer Q, Holladay 1, Holladay 2, SRK/T weinig van elkaar. Vanwege het gebrek aan literatuur over de Barrett Universal II voor korte ogen is niet duidelijk of deze formule beter voorspelt dan de gangbare lensformules die langer in gebruik zijn.
Het verschil tussen de formules is over het algemeen niet klinisch relevant, alle verschillen vallen binnen de 0,10 en 0,25 D.
Onderbouwing
De benodigde sterkte van de kunstlens om een voorgenomen postoperatieve refractieve uitkomst te behalen met de cataractoperatie wordt berekend met behulp van verschillende formules. Het nauwkeurig voorspellen van de postoperatieve refractie is belangrijk voor de patiënt, zeker met het gebruik van torische en/of multifocale en Extended Depth Of Focus kunstlenzen. Daarnaast is het percentage patiënten dat eindigt binnen 1 dioptrie van de beoogde refractie één van de uitkomstindicatoren voor cataractchirurgie. De prediction error wordt gedefinieerd als de postoperatieve refractie (sferisch equivalent) minus de beoogde refractie (i.e., sferisch equivalent van doelrefractie). In deze module wordt de prediction error vergeleken tussen verschillende lenssterkteformules.
1. Korte ooglengte (<22mm axiale lengte)
|
Laag GRADE |
De gemiddelde prediction error van de Haigis lijkt niet te verschillen van de Hoffer Q bij patiënten met een korte ooglengte (< 22 mm axiale lengte).
De gemiddelde prediction error van de Haigis lijkt niet te verschillen van de Holladay 1 bij patiënten met een korte ooglengte (< 22 mm axiale lengte).
De gemiddelde prediction error van de Haigis lijkt niet te verschillen van de Holladay 2 bij patiënten met een korte ooglengte (< 22 mm axiale lengte).
De gemiddelde prediction error van de Haigis lijkt niet te verschillen van de SRK/T bij patiënten met een korte ooglengte (< 22 mm axiale lengte).
De gemiddelde prediction error van de Barrett Universal II lijkt niet te verschillen van de SRK/T bij patiënten met een korte ooglengte (< 22 mm axiale lengte).
De gemiddelde prediction error van de Barrett Universal II lijkt niet te verschillen van de Holladay 2 bij patiënten met een korte ooglengte (< 22 mm axiale lengte).
Bronnen: (Carifi, 2015; Connell, 2019; Darcy, 2019; Day, 2012; Eom, 2014; Haigis, 2007; Kane, 2016; Kuthirummal, 2019; Moschos, 2014; Mustafa, 2019; Roberts, 2018; Roh, 2011; Shrivastana, 2019; Srivannaboon, 2013; Tang, 2020; Terzi, 2009; Voytsekhivskyy, 2017) |
2. Gemiddelde ooglengte (22 tot 26 mm axiale lengte)
|
Laag GRADE |
De gemiddelde prediction error van de Haigis lijkt, vanwege de lage bewijskracht, niet te verschillen van de Barrett Universal II bij patiënten met een gemiddelde ooglengte (22-26 mm axiale lengte).
Bronnen: (Kane, 2016) |
|
Redelijk GRADE |
De gemiddelde prediction error van de Haigis verschilt waarschijnlijk niet van de SRK/T bij patiënten met een gemiddelde ooglengte (22 tot 26 mm axiale lengte).
De gemiddelde prediction error van de Haigis verschilt waarschijnlijk niet van de Holladay 1 bij patiënten met een gemiddelde ooglengte (22 tot 26 mm axiale lengte).
De gemiddelde prediction error van de Holladay 2 verschilt waarschijnlijk niet van de Holladay 1 bij patiënten met een gemiddelde ooglengte (22 tot 26 mm axiale lengte).
De gemiddelde prediction error van de Barrett Universal II verschilt waarschijnlijk niet van de SRK/T bij patiënten met een gemiddelde ooglengte (22 tot 26 mm axiale lengte).
Bronnen: Connell, 2019; Darcy, 2019; Kane, 2016; Kuthirummal, 2019; Naeser, 2019; Roberts, 2018; Voytsekhivskyy, 2017. |
3. Lange ooglengte (> 26mm axiale lengte)
|
Laag GRADE |
De gemiddelde prediction error van de Haigis lijkt niet te verschillen van de Barrett Universal II bij patiënten met een lange ooglengte (> 26 mm axiale lengte).
De gemiddelde prediction error van de Haigis lijkt niet te verschillen van de SRK/T bij patiënten met een lange ooglengte (> 26 mm axiale lengte).
Bronnen: (Cooke, 2016; Darcy, 2019; Kane, 2016; Naeser, 2019; Rong, 2018; Savini, 2019; Terzi, 2009; Voytsekhivskyy, 2017; Wang, 2013; Zhang, 2019) |
|
Redelijk GRADE |
De gemiddelde prediction error van de Haigis verschilt statistisch significant van de Holladay 1 bij patiënten met een lange ooglengte (> 26 mm axiale lengte), echter is dit verschil niet klinisch relevant.
De gemiddelde prediction error van de Holladay 2 verschilt waarschijnlijk niet van de Holladay 1 bij patiënten met een lange ooglengte (> 26 mm axiale lengte).
Bronnen: (Cooke, 2016; Darcy, 2019; Kane, 2016; Naeser, 2019; Rong, 2018; Savini, 2019; Terzi, 2009; Wang, 2013; Zhang, 2019) |
Beschrijving studies
Wang (2018a) beschrijft een systematisch literatuuronderzoek naar de nauwkeurigheid van verschillende intraoculaire lenssterkteformules bij patiënten met korte ogen die cataractchirurgie ondergingen. De studie hanteerde de volgende inclusiecriteria: 1) ogen met een axiale lengte van minder dan 22,0 mm; 2) ogen die een ongecompliceerde cataractextractie of refractieve lensverwisseling ondergingen; 3) gebruik van ten minste twee typen lenssterkteformules; en 4) meten van de axiale lengte middels partiële coherentie interferometrie (PCI). De studie hanteerde de volgende exclusiecriteria: 1) een ziektegeschiedenis die de refractie beïnvloedt of status na refractiechirurgie; 2) multifocale, torische, piggyback of niet-in-de-lenszak gefixeerde lensimplantatie en 3) geen beschikbaarheid van predictie error data. Wang (2018a) dekt de literatuur tot en met oktober 2016. In totaal werden 10 observationele studies geïncludeerd, waarin 1161 ogen werden onderzocht. Over 8 van de 10 studies werd een meta-analyse uitgevoerd (Carifi, 2015; Day, 2012; Eom, 2014; Haigis, 2007; Kane, 2016; Roh, 2011; Srivannaboon, 2013; Terzi, 2009). Het aantal ogen binnen de individuele studies varieerde van 15 tot 608 ogen. De prediction error van de volgende lenssterkte formules werden bepaald: Haigis, Hoffer Q, Holladay 1, Holladay 2 en SRK/T.
Wang (2018b) beschrijft een systematisch literatuuronderzoek naar de nauwkeurigheid van verschillende intraoculaire lenssterkte formules bij patiënten met lange ogen die cataractchirurgie ondergingen. De studie hanteerde de volgende inclusiecriteria: 1) ogen met een axiale lengte van meer dan 24,5 mm; 2) ogen die een ongecompliceerde cataractextractie of refractieve lensverwisseling ondergingen; 3) gebruik van ten minste twee typen lenssterkte formules; en 4) meten van de axiale lengte middels partiële coherentie interferometrie (PCI). De studie hanteerde de volgende exclusiecriteria: 1) een ziektegeschiedenis die de refractie beïnvloedt of status na refractiechirurgie; 2) multifocale, torische, piggyback of niet-in-de-lenszak gefixeerde lensimplantatie; 3) geen beschikbaarheid van prediction error data; 4) geen toepassing van optimalisatie van lensconstanten en 5) review artikelen, discussienota’s of onderzoeken waarin dieren werden gebruikt. Wang (2018b) dekt de literatuur tot en met september 2017. In totaal werden 11 observationele studies geïncludeerd. In vier studies werden subgroepen van ogen met een axiale lengte van 24,5 mm tot 26,0 mm en meer dan 26,0 mm beschreven: Terzi (2009); Wang (2013); Cooke (2016); Kane (2016). De predictie error van de volgende lenssterkte formules werden bepaald: Barrett Universal II, Haigis, Hoffer Q, Holladay 1, Holladay 2 en SRK/T.
Tang (2020) beschrijft een retrospectief onderzoek naar de nauwkeurigheid van drie intraoculaire lenssterkte formules bij patiënten die cataractchirurgie ondergingen met ogen met axiale lengtes van minder dan 22,0 mm, 22,0 mm tot 25,0 mm en meer dan 25,0 mm. Tang (2020) vergeleek de Barrett Universal II met de Holladay 2 lenssterkteformule. De studie includeerde 909 ogen van 909 patiënten: 16 ogen met een axiale lengte van minder dan 22,0 mm, 762 ogen met een axiale lengte van 22,0 tot 25,0 mm en 125 ogen met een axiale lengte van meer dan 25,0 mm. De studie rapporteerde de volgende relevante uitkomstmaat: de gemiddelde absolute prediction error.
Connell (2019) beschrijft een retrospectieve case studie waarin de nauwkeurigheid van verschillende intraoculaire lenssterkteformules werd vergeleken bij patiënten die cataractchirurgie ondergingen met ogen met een axiale lengte van minder dan 22,0 mm, 22,0 mm tot 26,0 mm en meer dan 26,0 mm. Connell (2018) vergeleek de Barrett Universal II, Haigis, Hoffer Q, Holladay 2 en SRK/T lenssterkteformules. De studie includeerde 864 ogen van 864 patiënten: 46 patiënten met een axiale lengte van minder dan 22,0 mm, 774 patiënten met een axiale lengte van 22,0 mm tot 26 mm en 44 patiënten met een axiale lengte van meer dan 26,0 mm. De studie rapporteerde de volgende relevante uitkomstmaat: de gemiddelde absolute prediction error.
Darcy (2019) beschrijft een retrospectieve case studie waarin de nauwkeurigheid van verschillende intraoculaire lenssterkteformules werd vergeleken bij patiënten die cataractchirurgie ondergingen met ogen met een axiale lengte van minder dan 22,0 mm, 22,0 mm tot 26,0 mm en meer dan 26,0 mm. Darcy (2019) vergeleek de Barrett Universal II, Haigis, Hoffer Q, Holladay 1, Holladay 2 en SRK/T lenssterkteformules. De studie includeerde 10.930 ogen: 766 ogen met een axiale lengte van minder dan 22,0 mm, een axiale 9527 ogen met een axiale lengte van 22,0 mm tot 26,0 mm en 637 ogen met een axiale lengte van meer dan 26 mm. De studie rapporteerde de volgende relevante uitkomstmaat: de gemiddelde absolute prediction error.
Kuthirummal (2019) beschrijft een prospectief, observationeel onderzoek waarin de nauwkeurigheid van intraoculaire lenssterkteformules werden bepaald voor het voorspellen van intraoculaire lenssterkte bij patiënten die cataractchirurgie ondergingen met ogen met een axiale lengte van minder dan 22,0 mm, 22,0 mm tot 24,5 mm en meer dan 24,5 mm. Kuthirummal (2019) vergeleek de Barrett Universal II en de SRK/T lenssterkteformules. De studie includeerde 244 ogen van 244 patiënten: 53 ogen met een axiale lengte van minder dan 22,0 mm, 135 ogen met een axiale lengte van 22,0 mm tot 24,5 mm en 56 ogen met een axiale lengte van meer dan 24,5 mm. De studie rapporteerde de volgende relevante uitkomstmaat: de gemiddelde absolute prediction error.
Mustafa (2019) beschrijft een retrospectief onderzoek waarin de nauwkeurigheid van verschillende lenssterkteformules werden bepaald op refractieve uitkomsten bij patiënten die cataractchirurgie ondergingen met ogen met een axiale lengte van minder dan 22,0 mm. De studie vergeleek de Haigis, Hoffer Q, Holladay 1 en SRK/T lenssterkteformules. De studie includeerde 84 ogen van 84 patiënten. De studie rapporteerde de volgende relevante uitkomstmaat: de gemiddelde absolute prediction error.
Naeser (2019) beschrijft een retrospectieve case series waarin de nauwkeurigheid van twee thick-lens-formules (Naeser 1 en 2) vergeleken wordt met vijf vaak gebruikte lenssterkteformules bij patiënten die cataractchirurgie ondergingen met ogen met een axiale lengte van 22,0 mm tot 26,0 mm en met een axiale lengte van meer dan 26,0 mm. Naeser (2019) vergeleek de Barrett Universal II, Haigis, Hoffer Q, Holladay 1 en SRK/T lenssterkteformules. De studie includeerde 151 ogen van 151 patiënten: 135 ogen met een axiale lengte van 22,0 tot 26,0 mm en 16 ogen een axiale lengte van meer dan 26,0 mm. De studie rapporteerde de volgende relevante uitkomstmaat: de gemiddelde absolute prediction error.
Savini (2019) beschrijft een prospectieve studie waarin de nauwkeurigheid van oude en nieuwe lenssterkteformules zijn onderzocht bij patiënten die cataractchirurgie ondergingen bij ogen met een axiale lengte van minder dan 22,0 mm, 22,0 mm tot 24,5 mm, 24,51 mm tot 26,0 mm en meer dan 26,0 mm. Savini (2019) vergeleek de Barrett Universal II, Haigis, Hoffer Q, Holladay 1, Holladay 2 en SRK/T lenssterkteformules. De studie includeerde 155 ogen van 155 patiënten met een axiale lengte van minder dan 22,0 mm (n=3), een axiale lengte van 22,0 tot 24,5 mm (n=100), een axiale lengte van 24,51 tot 26 mm (n=29) en een axiale lengte van meer dan 26,0 mm (n=19). De studie rapporteerde de volgende relevante uitkomstmaat: de gemiddelde absolute prediction error.
Shrivastava (2019) beschrijft een retrospectieve studie waarin werd onderzocht in hoeverre de anterieure oogkamer diepte de nauwkeurigheid van verschillende intraoculaire lensformules beïnvloedt bij ogen met een axiale lengte van minder dan 22,0 mm. Shrivastava (2019) vergeleek de Haigis, Barrett Universal II, Hoffer Q, Holladay 1, Holladay 2 en SRK/T lenssterkteformules. De studie includeerde 85 ogen van 95 patiënten. De studie rapporteerde de volgende relevante uitkomstmaat: de gemiddelde absolute prediction error.
Zhang (2019) beschrijft een retrospectief onderzoek die het effect van verschillende methoden om lensconstanten te optimaliseren op de nauwkeurigheid van het berekenen van de intraoculaire lenssterkte evalueerde bij patiënten die cataractchirurgie ondergingen met ogen met een axiale lengte van meer dan 26,0 mm. Zhang (2019) vergeleek de Barrett Universal II, Hoffer Q, Holladay 1 en SRK/T lenssterkteformules. De studie includeerde 108 ogen van 94 patiënten. De studie rapporteerde de volgende relevante uitkomstmaat: de gemiddelde absolute prediction error.
Roberts (2018) beschrijft een retrospectieve case series die verschillende intraoculaire lenssterkteformules vergeleek bij patiënten die cataractchirurgie ondergingen bij ogen met een axiale lengte van minder dan 22,0 mm, 22,01 mm tot 24,5 mm en meer dan 24,51 mm. Roberts (2018) vergeleek de Barrett Universal II, Hoffer Q, Holladay 2 en SRK/T lenssterkteformules. De studie includeerde 400 ogen van 400 patiënten, met een axiale lengte van minder dan 22,0 mm (n=21), een axiale lengte van 22,01 tot 24,50 mm (n=289) en een axiale lengte van meer dan 24,51 mm (n=90). De studie rapporteerde de volgende relevante uitkomstmaat: de gemiddelde absolute prediction error.
Rong (2018) beschrijft een prospectieve case series die de nauwkeurigheid van verschillende lenssterkteformules vergeleek voor het berekenen van de intraoculaire lenssterkte bij patiënten die cataractchirurgie ondergingen met ogen met een axiale lengte van meer dan 26,0 mm. Rong (2018) vergeleek de Barrett Universal II en de Haigis lenssterkteformules. De studie includeerde 79 ogen van 79 patiënten. De studie rapporteerde de volgende relevante uitkomstmaat: de gemiddelde absolute prediction error.
Voytsekhivskyy (2017) beschrijft een observationele studie waarin de nauwkeurigheid van verschillende lenssterkteformules vergeleek voor het berekenen van de intraoculaire lenssterkte bij patiënten die cataractchirurgie ondergingen met ogen met een axiale lengte van minder dan 22,0 mm, 22,0 mm tot 24,5 mm, 24,5 mm tot 26,0 mm en meer dan 26,0 mm. Voytsekhivskyy (2017) vergeleek de Haigis, Hoffer Q, Holladay 1, Holladay 2 en SRK/T lenssterkteformules. De studie includeerde 823 ogen van 823 patiënten, met een axiale lengte van minder dan 22,0 mm (n=53), een axiale lengte van 22,0 tot 24,5 mm (n=320), een axiale lengte van 24,5 tot 26,0 mm (n=70) en een axiale lengte van meer dan 26,0 mm (n=51). De studie rapporteerde de volgende relevante uitkomstmaat: de gemiddelde absolute prediction error.
Moschos (2014) beschrijft een observationele studie die de nauwkeurigheid van verschillende lenssterkteformules vergeleek voor het berekenen van de lenssterkte bij patiënten met ogen met een axiale lengte van minder dan 22,0 mm. Moschos (2014) vergeleek de Haigis, Hoffer Q, Holladay 1 en SRK/T lenssterkteformules. De studie includeerde 69 ogen van 69 patiënten. De studie rapporteerde de volgende relevante uitkomstmaat: de gemiddelde absolute prediction error.
Resultaten
1. Korte ogen (axiale lengte < 22 mm)
Haigis versus Hoffer Q
Het gemiddelde verschil (mean difference, MD) in gemiddelde absolute prediction error tussen de Haigis en Hoffer Q is onderzocht in twaalf studies (Carifi, 2015; Day, 2012; Eom, 2014; Haigis, 2007; Kane, 2016; Moschos, 2014; Mustafa, 2019; Roh, 2011; Shrivastava, 2019; Srivannaboon, 2013; Terzi, 2009; Voytsekhivskyy, 2017). Het gepoolde gemiddelde verschil in gemiddelde absolute prediction error tussen de Haigis en de Hoffer Q is MD= -0,08 (95% BI= -0,15 tot -0,02), de gemiddelde absolute prediction error is niet klinisch relevant kleiner voor de Haigis (zie figuur 1).
Haigis versus Holladay 1
Het gemiddelde verschil (MD) in gemiddelde absolute prediction error tussen de Haigis en Holladay 1 is onderzocht in acht studies (Carifi, 2015; Day, 2012; Haigis, 2007; Kane, 2016; Moschos, 2014; Mustafa, 2019; Shrivastava, 2019; Voytsekhivskyy, 2017). Het gepoolde gemiddelde verschil in gemiddelde absolute prediction error tussen de Haigis en de Holladay 1 is MD= -0,08 (95% BI= -0,23 tot 0,06), de gemiddelde absolute prediction error is niet klinisch relevant kleiner voor de Haigis (zie figuur 1).
Haigis versus Holladay 2
Het gemiddelde verschil (MD) in gemiddelde absolute prediction error tussen de Haigis en Holladay 2 is onderzocht in zes studies (Carifi, 2015; Kane, 2016; Shrivastava, 2019; Srivannaboon, 2013; Terzi, 2009; Voytsekhivskyy, 2017). Het gepoolde gemiddelde verschil in gemiddelde absolute prediction error tussen de Haigis en de Holladay 2 is MD= 0,00 (95% BI= -0,06 tot 0,06), de gemiddelde absolute prediction error is niet klinisch relevant kleiner voor de Haigis (zie figuur 1).
Haigis versus SRK/T
Het gemiddelde verschil (MD) in gemiddelde absolute prediction error tussen de Haigis en SRK/T is onderzocht in tien studies (Carifi, 2015; Day, 2012; Haigis, 2007; Kane, 2016; Moschos, 2014; Mustafa, 2019; Roh, 2011; Shrivastava, 2019; Terzi, 2009; Voytsekhivskyy, 2017). Het gepoolde gemiddelde verschil in gemiddelde absolute prediction error tussen de Haigis en de SRK/T is MD= -0,13 (95% BI= -0,26 tot 0,00), de gemiddelde absolute prediction error is niet klinische relevant kleiner voor de Haigis (zie figuur 1).
Figuur 1 Gemiddelde absolute prediction error
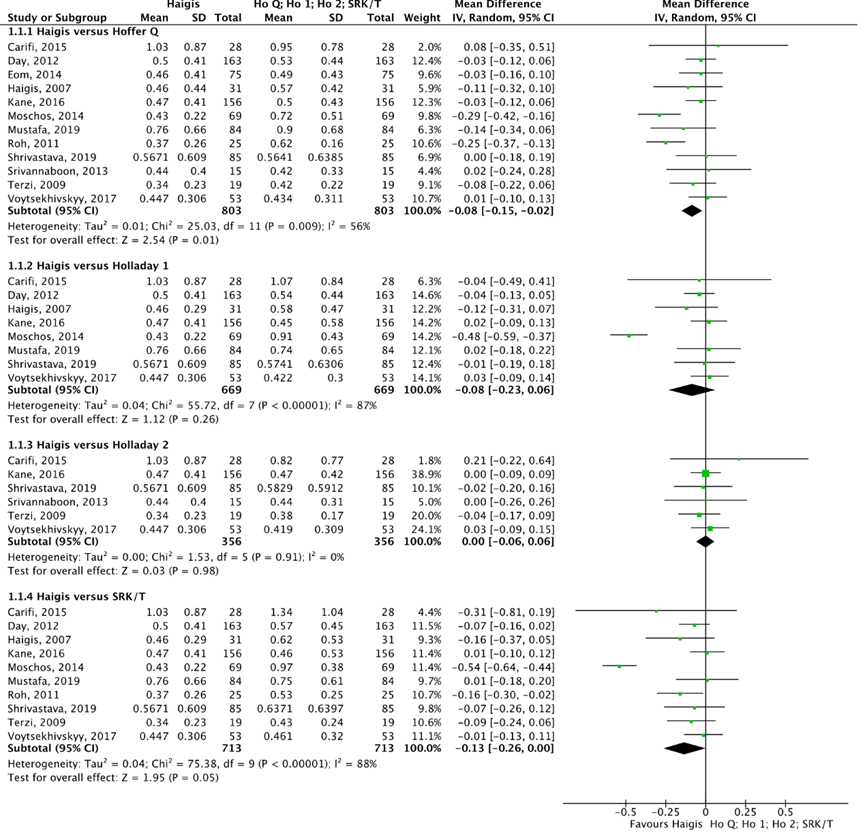
- Haigis versus Hoffer Q: Z=2.54 p=0.01; df: 11; I2: 56%; MD: -0.08 (BI: -0.15 tot -0.02);
- Haigis versus Holladay 1: Z=1.12; p=0.26; df: 7; I2: 87%; MD: -0.08 (BI: -0.23 tot 0.06);
- Haigis versus Holloday 2: Z=0.03; p=0.98; df: 5; I2: 0%; MD: 0.00 (BI: -0.06 tot 0.06);
- Haigis versus SRK/T: Z=1.95; p=0.05; df: 9; I2: 88%; MD: -0.13 (BI: -0.26 tot 0.00).
Z: p-waarde van het gepoolde effect; df: degrees of freedom (vrijheidsgraden); I2: statistische heterogeniteit; BI: betrouwbaarheidsinterval
Barrett Universal II versus SRK/T
Het gemiddelde verschil (MD) in gemiddelde absolute prediction error tussen de Barrett Universal II en SRK/T is onderzocht in drie studies (Kuthirummal, 2019; Roberts, 2018; Shrivastana, 2019). Het gepoolde gemiddelde verschil in gemiddelde absolute prediction error tussen de Barrett Universal II en de SRK/T is MD= -0,12 (95% BI= -0,27 tot 0.04), de gemiddelde absolute prediction error is niet klinisch relevant kleiner voor de Barrett Universal II (zie figuur 2).
Figuur 2 Gemiddelde absolute prediction error

- Barrett Universal II versus SRK/T: Z=1.43; p=0.15; d2: 1; I2: 57%; MD: -0.12 (BI: -0.27 tot 0.04).
Z: p-waarde van het gepoolde effect; df: degrees of freedom (vrijheidsgraden); I2: statistische heterogeniteit; BI: betrouwbaarheidsinterval
Barrett Universal II versus Holladay 2
Het gemiddelde verschil (MD) in gemiddelde absolute prediction error tussen de Barrett Universal II en Holladay 2 is onderzocht in drie studies (Roberts, 2018; Shrivastana, 2019; Tang, 2020). De resultaten van de studies kunnen niet worden gepoold vanwege heterogeniteit in statistische analyses. Roberts (2018) rapporteerde een gemiddeld verschil in gemiddelde absolute prediction error tussen de Barrett Universal II (gemiddelde= 0,43, SD=0,36) en de Holladay 2 (gemiddelde= 0,52, SD=0,52) van MD= -0,09 (95%BI= -0,36 tot 0,18; p=0,51, geen verschil tussen beide formules). Shrivastana (2019) rapporteerde een gemiddeld verschil in gemiddelde absolute prediction error tussen de Barret Universal II (gemiddelde= 0,6006, SD= 0,6201) en de Holladay 2 (gemiddelde= 0,5829, SD= 0,5912) van MD= -0,02 (95% CI= -0,27 tot 0,20; p=0,85, geen verschil tussen beide formules). Tang (2020) rapporteerde een gemiddelde absolute prediction error van de Barrett Universal II van 0,535 versus 0,512 van de Holladay 2.
De studies van Connell (2019) en Darcy (2019) onderzochten ook de gemiddelde absolute prediction error van de Haigis, Hoffer Q, Holladay 1, Holladay 2 en SRK/T lenssterkteformules bij korte ogen. Echter, deze studies toetsten niet op statistische significantie. De gemiddelde absolute prediction error van de afzonderlijke studies per lenssterkteformule zijn weergegeven in tabel 1:
Tabel 1 Gemiddelde absolute prediction error voor een axiale lengte van minder dan 22 mm (korte ogen) van twee individuele studies welke niet hebben getoetst op statistische significantie
|
Studie |
Haigis |
Hoffer Q |
Holladay 1 |
Holladay 2 |
SRK/T |
|
Connell, 2019 |
0,472 |
0,476 |
0,438 |
0,483 |
0,475 |
|
Darcy, 2019 |
0,486 |
0,478 |
0,461 |
0,458 |
0,492 |
2. Gemiddelde ogen (axiale lengte 22 tot 26 mm)
Haigis versus Barrett Universal II
Het gemiddelde verschil (MD) in gemiddelde absolute prediction error tussen de Haigis en de Barrett Universal II is onderzocht in één studie (Kane, 2016). De gemiddelde absolute prediction error van de Haigis was 0,409 (SD 0,429) versus 0,338 (SD 0,271) van de Barrett Universal II (MD= -0,07 (95%BI= -0,12 tot -0,02; p=0,007), de gemiddelde absolute prediction is statistisch significant kleiner, maar niet klinisch relevant kleiner voor de Barrett Universal II.
Haigis versus SRK/T
Het gemiddelde verschil (MD) in gemiddelde absolute prediction error tussen de Haigis en de SRK/T is onderzocht in twee studies (Kane, 2016; Voytsekhivskyy, 2017). Het gepoolde gemiddelde verschil in absolute prediction error tussen de Haigis en de SRK/T is MD= -0.02 (95%BI=-0.05 tot 0.02), de gemiddelde absolute prediction error is niet klinisch relevant kleiner voor de Haigis (zie figuur 3).
Haigis versus Holladay 1
Het gemiddelde verschil (MD) in gemiddelde absolute prediction error tussen de Haigis en de Holladay 1 is onderzocht in twee studies (Kane, 2016; Voytsekhivskyy, 2017). Het gepoolde gemiddelde verschil in absolute prediction error tussen de Haigis en de Holladay 1 is MD= 0.01 (95%BI= -0.02 tot 0.04), de gemiddelde absolute prediction error is niet klinisch relevant kleiner voor de Holladay 1 (zie figuur 3).
Holladay 2 versus Holladay 1
Het gemiddelde verschil (MD) in gemiddelde absolute prediction error tussen de Holladay 2 en de Holladay 1 is onderzocht in twee studies (Kane, 2016; Voytsekhivskyy, 2017). Het gepoolde gemiddelde verschil in absolute prediction error tussen de Holladay 2 en de Holladay 1 is MD= -0.01 (95%BI= -0.05 tot 0.02), de gemiddelde absolute prediction error is niet klinisch relevant kleiner voor de Holladay 2 (zie figuur 3).
Figuur 3 Gemiddelde absolute prediction error
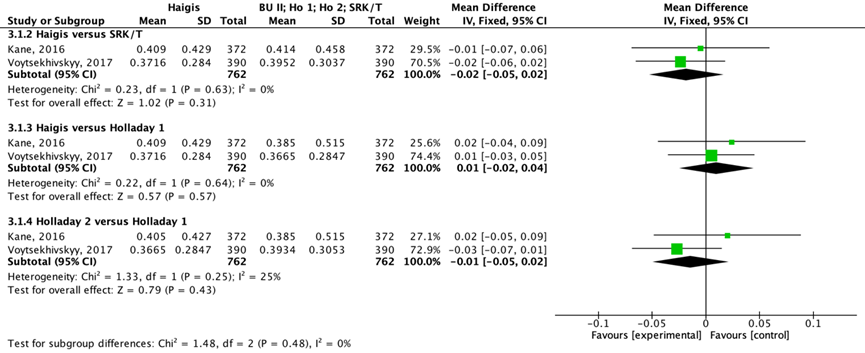
- Haigis versus SRK/T: Z=1.02; p=0.31; df: 1; I2: 0%; MD: -0.02 (BI: -0.05 tot 0.04);
- Haigis versus Holladay 1: Z=0.5; p=0.57; df: 1; I2: 0%; MD: 0.01 (BI:-0.02 tot 0.04);
- Holladay 2 versus Holladay 1: Z=0.79; p=0.43; df: 1; I2: 25%; MD: -0.01 (BI: -0.05 tot 0.02);
Z: p-waarde van het gepoolde effect; df: degrees of freedom (vrijheidsgraden); I2: statistische heterogeniteit; BI: betrouwbaarheidsinterval
Barrett Universal II versus SRK/T
Het gemiddelde verschil (MD) in gemiddelde absolute prediction error tussen de Barrett Universal II en SRK/T is onderzocht in twee studies (Kuthirummal, 2019; Roberts, 2018). Het gepoolde gemiddelde verschil in gemiddelde absolute prediction error tussen de Barrett Universal II en de SRK/T is (MD= -0,01 (95% BI= -0,05 tot 0,04; p=0,22), de gemiddelde absolute prediction is niet klinisch relevant kleiner voor de Barrett Universal II (zie figuur 4).
Figuur 4 Gemiddelde absolute prediction error

- Barrett Universal II versus SRK/T: Z=1.52; p=0.81; df: 1; I2: 34%; MD: -0.01 (BI: -0.05 tot 0.04).
Z: p-waarde van het gepoolde effect; df: degrees of freedom (vrijheidsgraden); I2: statistische heterogeniteit; BI: betrouwbaarheidsinterval
De studies van Connell (2019), Darcy (2019) en Naeser (2019) onderzochten ook de gemiddelde absolute prediction error van de Barrett Universal II, Haigis, Holladay 1, Holladay 2 en SRK/T lenssterkteformules bij gemiddelde ogen. Echter, deze studie kon niet worden meegenomen in een meta-analyse, omdat in de studie geen SD werd gerapporteerd. De gemiddelde absolute prediction error van de studies van Connell (2019), Darcy (2019) en Naeser (2019) per lenssterkteformule is weergegeven in tabel 2:
Tabel 2 gemiddelde absolute prediction error voor een axiale lengte van 22 tot 26 mm (gemiddelde ogen) van drie individuele studies welke niet hebben getoetst op statistische significantie
|
Studie |
Barrett Universal II |
Haigis |
Hoffer Q |
Holladay 1 |
Holladay 2 |
SRK/T |
|
Connell, 2019 |
0,344 |
0,353 |
X |
0,343 |
0,350 |
0,360 |
|
Darcy, 2019 |
0,385 |
0,402 |
0,401 |
0,387 |
0,387 |
0,399 |
|
Naeser, 2019 |
0,240 |
0,240 |
0,280 |
0,290 |
X |
0,270 |
3. Lange ogen (axiale lengte > 26 mm)
Haigis versus Barrett Universal II
Het gemiddelde verschil (MD) in gemiddelde absolute prediction error tussen de Haigis en Barrett Universal II is onderzocht in drie studies (Cooke, 2016; Kane, 2016; Rong, 2018). Het gepoolde gemiddelde verschil in gemiddelde absolute prediction error tussen de Haigis en de Barrett Universal II is MD= 0,08 (95% BI= -0,01 tot 0,16), de gemiddelde absolute prediction error is niet klinische relevant kleiner voor de Barrett Universal II (zie figuur 5).
Haigis versus SRK/T
Het gemiddelde verschil (MD) in gemiddelde absolute prediction error tussen de Haigis en SRK/T is onderzocht in vijf studies (Cooke, 2016; Kane, 2016; Terzi, 2009; Voytsekhivskyy, 2017; Wang, 2013). Het gepoolde gemiddelde verschil in gemiddelde absolute prediction error tussen de Haigis en de SRK/T is MD= -0,02 (95% BI= -0,07 tot 0,03), de gemiddelde absolute prediction error is niet klinische relevant kleiner voor de Haigis (zie figuur 5).
Haigis versus Holladay 1
Het gemiddelde verschil (MD) in gemiddelde absolute prediction error tussen de Haigis en Holladay 1 is onderzocht in vier studies (Cooke, 2016; Kane, 2016; Voytsekhivskyy, 2017; Wang, 2013). Het gepoolde gemiddelde verschil in gemiddelde absolute prediction error tussen de Haigis en de Holladay 1 is MD= -0,09 (95% BI= -0,17 tot -0,01), de gemiddelde absolute prediction error is niet klinisch relevant kleiner voor de Haigis (zie figuur 5).
Holladay 2 versus Holladay 1
Het gemiddelde verschil (MD) in gemiddelde absolute prediction error tussen de Holladay 2 en Holladay 1 is onderzocht in drie studies (Cooke, 2016; Kane, 2016; Voytsekhivskyy, 2017). Het gepoolde gemiddelde verschil in gemiddelde absolute prediction error tussen de Holladay 2 en de Holladay 1 is MD= -0,03 (95% BI= -0,12 tot 0,06), de gemiddelde absolute prediction error is niet klinisch relevant kleiner voor de Holladay 2 (zie figuur 5).
Figuur 5 Gemiddelde absolute prediction error
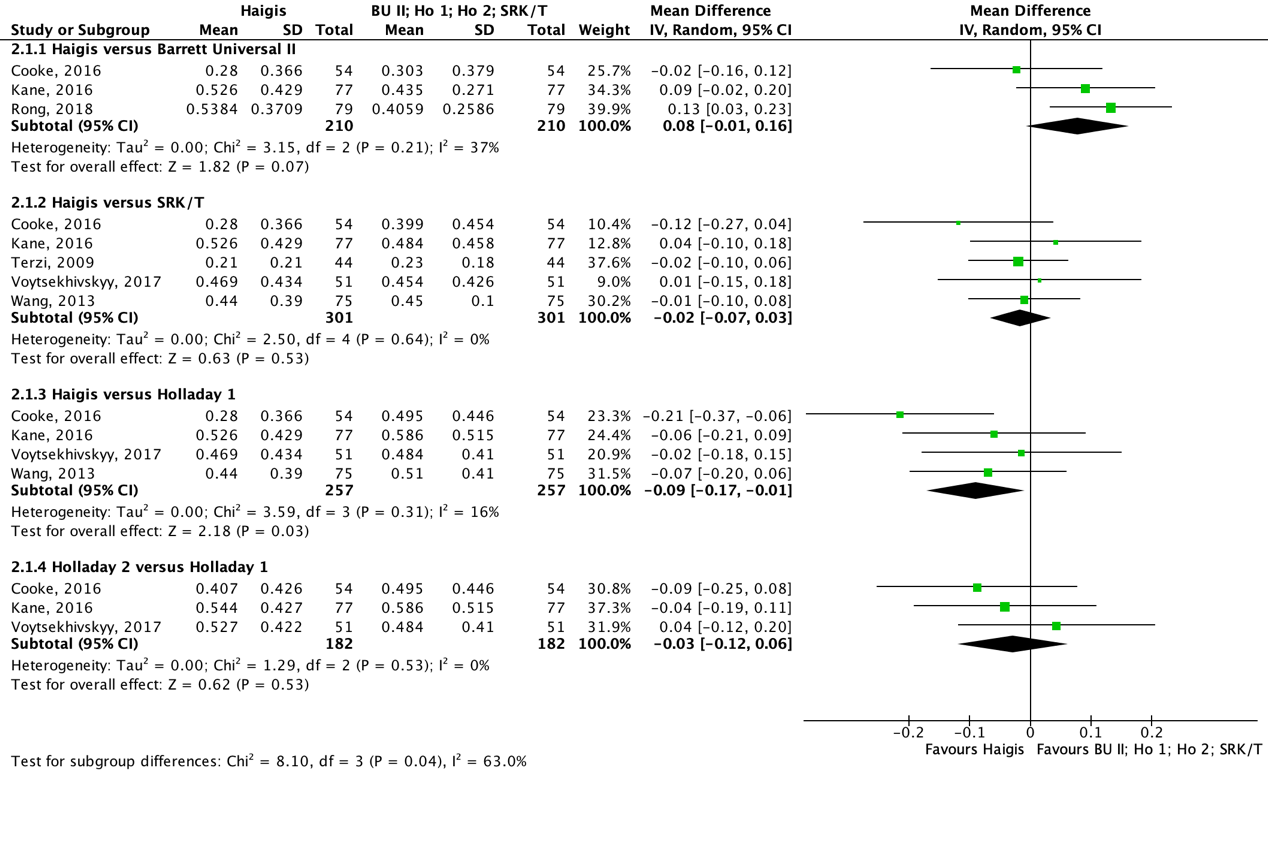
- Haigis versus Barrett Universal II: Z=1.82; p=0.07; df: 2; I2: 37%; MD: 0.08 (BI: -0.01 tot 0.16);
- Haigis versus SRK/T: Z=0.63; p=0.53; df: 4; I2: 0%; MD: -0.02 (BI: -0.07 tot 0.03);
- Haigis versus Holladay 1: Z=2.18; p=0.03; df: 3; I2: 16%; MD: -0.09 (BI; -0.17 tot -0.01);
- Holladay 2 versus Holladay 1: Z=0.62; p=0.53; df: 2; I2: 0%; MD: -0.03 (BI: -0.12 tot 0.06).
Z: p-waarde van het gepoolde effect; df: degrees of freedom (vrijheidsgraden); I2: statistische heterogeniteit; BI: betrouwbaarheidsinterval.
De studies van Connell (2019), Darcy (2019), Naeser (2019), Savini (2019) en Zhang (2019) onderzochten ook de gemiddelde absolute prediction error van de Barrett Universal II, Haigis, Holladay 1, Holladay 2 en SRK/T lenssterkteformules bij lange ogen. Echter, deze studies konden niet worden meegenomen in de meta-analyse, omdat in geen van de studies een SD werd gerapporteerd. De gemiddelde absolute prediction error van de afzonderlijke studies per lenssterkteformule zijn weergegeven in tabel 3:
Tabel 3 gemiddelde absolute prediction error voor een axiale lengte van meer dan 26 mm (lange ogen) van vijf individuele studies welke niet hebben getoetst op statistische significantie
|
Studie |
Haigis |
Barrett Universal II |
Holladay 1 |
Holladay 2 |
SRK/T |
|
Connell, 2019 |
0,322 |
0,331 |
0,545 |
0,348 |
0,407 |
|
Darcy, 2019 |
0,359 |
0,338 |
0,475 |
0,352 |
0,363 |
|
Naeser, 2019 |
0,15 |
0,20 |
0,45 |
Niet gerapporteerd |
0,15 |
|
Savini, 2019 |
0,298 |
0,253 |
0,582 |
0,483 |
0,312 |
|
Zhang, 2019 |
0,65 |
0,42 |
0,89 |
Niet gerapporteerd |
0,72 |
Bewijskracht van de literatuur
1. Korte ooglengte (< 22 mm axiale lengte)
- Haigis versus Hoffer - De bewijskracht voor de uitkomstmaat gemiddelde prediction error bij patiënten met een korte ooglengte (< 22 mm) is afkomstig uit observationeel onderzoek. Omdat de formules zijn onderzocht binnen dezelfde patiënt, is selectiebias uitgesloten. De bewijskracht van de literatuur start daarom niet op laag maar op hoog. De bewijskracht is met twee niveaus verlaagd vanwege heterogeniteit in de studieresultaten (inconsistentie) en het kleine aantal patiënten (imprecisie). De bewijskracht is LAAG.
- Haigis versus SRK/T - De bewijskracht voor de uitkomstmaat gemiddelde prediction error bij patiënten met een korte ooglengte (< 22 mm) is afkomstig uit observationeel onderzoek. Omdat de formules zijn onderzocht binnen dezelfde patiënt, is selectiebias uitgesloten. De bewijskracht van de literatuur start daarom niet op laag maar op hoog. De bewijskracht is met twee niveaus verlaagd vanwege heterogeniteit in de studieresultaten (inconsistentie) en het kleine aantal patiënten (imprecisie). De bewijskracht is LAAG.
- Haigis versus Holladay 1 - De bewijskracht voor de uitkomstmaat gemiddelde prediction error bij patiënten met een korte ooglengte (< 22 mm) is afkomstig uit observationeel onderzoek. Omdat de formules zijn onderzocht binnen dezelfde patiënt, is selectiebias uitgesloten. De bewijskracht van de literatuur start daarom niet op laag maar op hoog. De bewijskracht is met twee niveaus verlaagd vanwege heterogeniteit in de studieresultaten (inconsistentie) en het kleine aantal patiënten (imprecisie). De bewijskracht is LAAG.
- Haigis versus Holladay 2 - De bewijskracht voor de uitkomstmaat gemiddelde prediction error bij patiënten met een korte ooglengte (< 22 mm) is afkomstig uit observationeel onderzoek. Omdat de formules zijn onderzocht binnen dezelfde patiënt, is selectiebias uitgesloten. De bewijskracht van de literatuur start daarom niet op laag maar op hoog. De bewijskracht is met twee niveaus verlaagd vanwege heterogeniteit in de studieresultaten (inconsistentie) en het kleine aantal patiënten (imprecisie). De bewijskracht is LAAG.
- Barrett Universal II versus SRK/T - De bewijskracht voor de uitkomstmaat gemiddelde prediction error bij patiënten met een korte ooglengte (< 22 mm) is afkomstig uit observationeel onderzoek. Omdat de formules zijn onderzocht binnen dezelfde patiënt, is selectiebias uitgesloten. De bewijskracht van de literatuur start daarom niet op laag maar op hoog. De bewijskracht is met twee niveaus verlaagd vanwege het doorkruisen van het betrouwbaarheidsinterval van de grens van klinische relevantie en het kleine aantal patiënten (beide imprecisie). De bewijskracht is LAAG.
- Barrett Universal II versus Holladay 2 - De bewijskracht voor de uitkomstmaat gemiddelde prediction error bij patiënten met een korte ooglengte (< 22 mm) is afkomstig uit observationeel onderzoek. Omdat de formules zijn onderzocht binnen dezelfde patiënt, is selectiebias uitgesloten. De bewijskracht van de literatuur start daarom niet op laag maar op hoog. De bewijskracht is met twee niveaus verlaagd vanwege het doorkruisen van het betrouwbaarheidsinterval van de grens van klinische relevantie en het kleine aantal patiënten (beide imprecisie). De bewijskracht is LAAG.
2. Gemiddelde ooglengte (22 tot 26 mm axiale lengte)
- Haigis versus Barrett Universal II - De bewijskracht voor de uitkomstmaat gemiddelde prediction error bij patiënten met een gemiddelde ooglengte (axiale lengte 22 tot 26 mm) is afkomstig uit observationeel onderzoek. Omdat de formules zijn onderzocht binnen dezelfde patiënt, is selectiebias uitgesloten. De bewijskracht van de literatuur start daarom niet op laag maar op hoog. De bewijskracht is met één niveau verlaagd vanwege het kleine aantal patiënten (imprecisie); één enkele studie (imprecisie). De bewijskracht is LAAG.
- Haigis versus SRK/T - De bewijskracht voor de uitkomstmaat gemiddelde prediction error bij patiënten met een gemiddelde ooglengte (axiale lengte 22 tot 26 mm) is afkomstig uit observationeel onderzoek. Omdat de formules zijn onderzocht binnen dezelfde patiënt, is selectiebias uitgesloten. De bewijskracht van de literatuur start daarom niet op laag maar op hoog. De bewijskracht is met één niveau verlaagd vanwege het kleine aantal patiënten (imprecisie). De bewijskracht is REDELIJK.
- Haigis versus Holladay 1 - De bewijskracht voor de uitkomstmaat gemiddelde prediction error bij patiënten met een gemiddelde ooglengte (axiale lengte 22 tot 26 mm) is afkomstig uit observationeel onderzoek. Omdat de formules zijn onderzocht binnen dezelfde patiënt, is selectiebias uitgesloten. De bewijskracht van de literatuur start daarom niet op laag maar op hoog. De bewijskracht is met één niveau verlaagd vanwege het kleine aantal patiënten (imprecisie). De bewijskracht is REDELIJK.
- Holladay 2 versus Holladay 1 - De bewijskracht voor de uitkomstmaat gemiddelde prediction error bij patiënten met een gemiddelde ooglente (axiale lengte 22 tot 26 mm) is afkomstig uit observationeel onderzoek. Omdat de formules zijn onderzocht binnen dezelfde patiënt, is selectiebias uitgesloten. De bewijskracht van de literatuur start daarom niet op laag maar op hoog. De bewijskracht is met één niveau verlaagd vanwege het kleine aantal patiënten (imprecisie). De bewijskracht is REDELIJK.
- Barrett Universal II versus SRK/T - De bewijskracht voor de uitkomstmaat gemiddelde prediction error bij patiënten met een gemiddelde ooglengte (axiale lengte 22 tot 26 mm) is afkomstig uit observationeel onderzoek. Omdat de formules zijn onderzocht binnen dezelfde patiënt, is selectiebias uitgesloten. De bewijskracht van de literatuur start daarom niet op laag maar op hoog. De bewijskracht is met één niveau verlaagd vanwege het kleine aantal patiënten (imprecisie). De bewijskracht is REDELIJK.
3. Lange ooglengte (> 26mm axiale lengte)
- Haigis versus Barrett Universal II - De bewijskracht voor de uitkomstmaat gemiddelde prediction error bij patiënten met een lange ooglengte (axiale lengte > 26 mm) is afkomstig uit observationeel onderzoek. Omdat de formules zijn onderzocht binnen dezelfde patiënt, is selectiebias uitgesloten. De bewijskracht van de literatuur start daarom niet op laag maar op hoog. De bewijskracht is met twee niveaus verlaagd vanwege heterogeniteit in de studieresultaten (inconsistentie) en het kleine aantal patiënten (imprecisie). De bewijskracht is LAAG.
- Haigis versus SRK/T - De bewijskracht voor de uitkomstmaat gemiddelde prediction error bij patiënten met een lange ooglengte (axiale lengte > 26 mm) is afkomstig uit observationeel onderzoek. Omdat de formules zijn onderzocht binnen dezelfde patiënt, is selectiebias uitgesloten. De bewijskracht van de literatuur start daarom niet op laag maar op hoog. De bewijskracht is met twee niveaus verlaagd vanwege heterogeniteit in de studieresultaten (inconsistentie) en het kleine aantal patiënten (imprecisie). De bewijskracht is LAAG.
- Haigis versus Holladay 1 - De bewijskracht voor de uitkomstmaat gemiddelde prediction error bij patiënten met een lange ooglengte (axiale lengte > 26 mm) is afkomstig uit observationeel onderzoek. Omdat de formules zijn onderzocht binnen dezelfde patiënt, is selectiebias uitgesloten. De bewijskracht van de literatuur start daarom niet op laag maar op hoog. De bewijskracht is met één niveau verlaagd vanwege het kleine aantal patiënten (imprecisie). De bewijskracht is REDELIJK.
- Holladay 2 versus Holladay 1 - De bewijskracht voor de uitkomstmaat gemiddelde prediction error bij patiënten met een lange ooglengte (axiale lengte > 26 mm) is afkomstig uit observationeel onderzoek. Omdat de formules zijn onderzocht binnen dezelfde patiënt, is selectiebias uitgesloten. De bewijskracht van de literatuur start daarom niet op laag maar op hoog. De bewijskracht is met één niveau verlaagd vanwege het kleine aantal patiënten (imprecisie). De bewijskracht is REDELIJK.
Om de uitgangsvraag te kunnen beantwoorden is er een systematische literatuuranalyse verricht naar de volgende zoekvraag:
Welke lensformule leidt tot de kleinste afwijking van doelrefractie na cataractchirurgie?
P: patiënten met een indicatie voor cataractchirurgie;
I: IOL formules: Barrett Universal II, Haigis, Hoffer Q, Holladay 1, Holladay 2, SRK/T;
C: de andere onder de interventie genoemde formules;
O: prediction error.
Relevante uitkomstmaten
De werkgroep achtte prediction error een voor de besluitvorming cruciale uitkomstmaat. De werkgroep definieerde niet a priori de genoemde uitkomstmaten, maar hanteerde de in de studies gebruikte definities. De werkgroep definieerde 0,25 dioptrie (D) als een klinisch (voor de patiënt) relevant verschil. De werkgroep definieerde korte ogen als ogen met een axiale lengte < 22 mm, gemiddelde ogen als ogen met een axiale lengte tussen 22 en 26 mm en lange ogen als ogen met een axiale lengte > 26 mm.
Zoeken en selecteren (Methode)
In de databases Medline (via OVID) en Embase (via Embase.com) is op 5 maart 2020 met relevante zoektermen gezocht naar systematische reviews, gerandomiseerd gecontroleerd onderzoek (RCT’s) en observationeel onderzoek. De zoekverantwoording is weergegeven onder het tabblad Verantwoording. De literatuurzoekactie leverde 385 treffers op. Studies werden geselecteerd op grond van de volgende selectiecriteria: systematische review (gezocht in ten minste twee relevante databases, risk of bias beoordeling aanwezig en de resultaten van individuele studies voldoende gepresenteerd) of RCT of observationeel onderzoek waarin een vergelijking is gemaakt tussen minstens twee lensformules bij > 100 (50 per arm) patiënten. Op basis van titel en abstract werden in eerste instantie 40 studies voorgeselecteerd. Na raadpleging van de volledige tekst, werden vervolgens 28 studies geëxcludeerd (zie exclusietabel onder het tabblad Verantwoording) en 12 studies definitief geselecteerd. Halverwege 2020 werd er een systematische review (Kane, 2020) gepubliceerd. Aan de hand van deze review zijn nog drie studies toegevoegd.
Resultaten
Vijftien onderzoeken zijn opgenomen in de literatuuranalyse. De belangrijkste studiekarakteristieken en resultaten zijn opgenomen in de evidencetabellen. De beoordeling van de individuele studieopzet (risk of bias) is opgenomen in de risk-of-biastabellen.
- Wang, Q., Jiang, W., Lin, T., Wu, X., Lin, H., & Chen, W. (2018a). Meta‐analysis of accuracy of intraocular lens power calculation formulas in short eyes. Clinical & experimental ophthalmology, 46(4), 356-363.
- Wang, Q., Jiang, W., Lin, T., Zhu, Y., Chen, C., Lin, H., & Chen, W. (2018b). Accuracy of intraocular lens power calculation formulas in long eyes: a systematic review and meta‐analysis. Clinical & experimental ophthalmology, 46(7), 738-749.
- Connell, B. J., & Kane, J. X. (2019). Comparison of the Kane formula with existing formulas for intraocular lens power selection. BMJ open ophthalmology, 4(1), e000251.
- Cooke, D. L., & Cooke, T. L. (2016). Comparison of 9 intraocular lens power calculation formulas. Journal of Cataract & Refractive Surgery, 42(8), 1157-1164.
- Darcy K, Gunn D, Tavassoli S, Sparrow J, Kane JX, Assessment of the accuracy of new and updated IOL power calculation formulas in 10930 eyes from the UK National Health Service., Journal of Cartaract & Refractive Surgery (2019), doi:https://doi.org/10.1016/j.jcrs.2019.08.014
- Kuthirummal, N., Vanathi, M., Mukhija, R., Gupta, N., Meel, R., Saxena, R., & Tandon, R. (2020). Evaluation of Barrett universal II formula for intraocular lens power calculation in Asian Indian population. Indian Journal of Ophthalmology, 68(1), 59.
- Mustafa, M. Z., Khan, A. A., Bennett, H., Tatham, A. J., & Wright, M. (2019). Accuracy of biometric formulae in hypermetropic patients undergoing cataract surgery. European journal of ophthalmology, 29(5), 510-515.
- Næser, K., & Savini, G. (2019). Accuracy of thick-lens intraocular lens power calculation based on cutting-card or calculated data for lens architecture. Journal of Cataract & Refractive Surgery, 45(10), 1422-1429.
- Roberts, T. V., Hodge, C., Sutton, G., Lawless, M., & Contributors to the Vision Eye Institute IOL Outcomes Registry. (2018). Comparison of Hill‐radial basis function, Barrett Universal and current third generation formulas for the calculation of intraocular lens power during cataract surgery. Clinical & Experimental Ophthalmology, 46(3), 240-246.
- Rong, X., He, W., Zhu, Q., Qian, D., Lu, Y., & Zhu, X. (2019). Intraocular lens power calculation in eyes with extreme myopia: Comparison of Barrett Universal II, Haigis, and Olsen formulas. Journal of Cataract & Refractive Surgery, 45(6), 732-737.
- Savini, G., Hoffer, K. J., Shammas, H. J., Aramberri, J., Huang, J., & Barboni, P. (2017). Accuracy of a new swept-source optical coherence tomography biometer for IOL power calculation and comparison to IOLMaster. Journal of refractive surgery, 33(10), 690-695.
- Zhang, J. Q., Zou, X. Y., Zheng, D. Y., Chen, W. R., Sun, A., & Luo, L. X. (2019). Effect of lens constants optimization on the accuracy of intraocular lens power calculation formulas for highly myopic eyes. International Journal of Ophthalmology, 12(6), 943.
|
Study reference |
Study characteristics |
Patient characteristics |
Intervention (I) |
Comparison / control (C) |
Follow-up |
Outcome measures and effect size |
Comments |
|
Wang, 2018
(short eyes)
|
SR and meta-analysis of observational studies
Literature search up to October, 2016
A: Haigis, 2007 B: Gavin and Hammond C: Terzi, 2009 D: Aristodemou, 2011 E: Roh, 2011 F: Day, 2012 G: Srivannaboon, 2013 H: Eom, 2014 I: Carifi, 2015 J: Kane, 2016
Study design: RCT [parallel / cross-over], cohort [prospective / retrospective], case-control
Setting and Country:
Source of funding and conflicts of interest: [commercial / non-commercial / industrial co-authorship]
|
Inclusion criteria SR:
(i) eyes with AL less than 22.00 mm;
(ii) eyes undergoing uncomplicated cataract or clear lens extraction and IOL implantation;
(iii) at least two types of the target IOL power calculation formula (Haigis, Hoffer Q, Holladay 1, Holladay 2, SRK/T, SRK II) used;
(iv) AL measured by partial coherence interferometry (PCI).
Exclusion criteria SR:
(i) patients with a prior history of disease affecting refraction or corneal refractive surgery;
(ii) multifocal, toric, piggyback or not in-the-bag fixated IOL implantation, (iii) MAE data unavailable.
10 studies included
Important patient characteristics at baseline: Number of patients; characteristics important to the research question and/or for statistical adjustment (confounding in cohort studies); for example, age, sex, bmi,...
N (patients/eyes), mean age (range)
A: NA/31, NA yrs B: 41/41, NA yrs C: 11/19, 53 ± 7 yrs D: NA/608, NA yrs E: 17/25, 70.6 ± 5.5 (61-80) yrs F: 97/163, 57 ± 10 (33-82) G: NA/15, NA yrs H: 75/75, 70.1 ± 6.8 (52-85) I: 28/28, 72 ± 10 (55-92) J: 156/156, NA yrs
Sex (M/F): A: NA B: NA C: NA D: NA E: NA F: NA G: NA H: NA I: NA J: NA
Groups comparable at baseline? |
Describe intervention:
A: Haigis B: Hoffer Q C: Haigis D: Hoffer Q E: Haigis F: Haigis G: Haigis H: Haigis I: Haigis J: Haigis
|
Describe control:
A: Hoffer Q; Holladay 1; Holladay 2; SRK/T; SRK II B: SRK/T C: Hoffer Q; Holladay 2; SRK/T; SRK T D: Holladay 1; SRK/T E: Hoffer Q; SRK/T; SRK II F: Hoffer Q; Holladay 1; SRK/T G: Hoffer Q; Holladay 2 H: Hoffer Q I: Hoffer Q; Holladay 1; Holladay 2; SRK/T; SRK II J: Hoffer Q; Holladay 1; Holladay 2; SRK/T
|
End-point of follow-up (post-operative refraction):
A: NA B: 2-3 weeks C: 1 month D: ≥ 4 weeks E: 2 months F: 5.3 weeks (range 2-17.7) G: 3 months H: 3-10 weeks I: < 4 weeks J: 2 weeks
|
Haigis vs Holladay 2
Mean difference [95% CI]:
C: -0.04 [95% CI: -0.17, 0.09] G: 0.00 [95% CI:-0.26, 0.26] I: 0.21 [95% CI: -0.22, 0.64] J: 0.00 [95% CI: -0.09, 0.09]
Pooled effect (random effects model / fixed effects model):
-0.01 [95% CI -0.08 to 0.06] favoring Haigis
Heterogeneity (I2): 0%
Haigis vs Hoffer Q
Mean difference [95% CI]:
I: 0.08 [95% CI: -0.35, 0.51] F: -0.03 [95% CI: -0.12, 0.06] H: -0.03 [95% CI: -0.16, 0.10] A: -0.11 [95% CI: -0.3, 0.10] J: -0.03 [95% CI: -0.12,0.06] E: -0.25 [95% CI: -0.37, 0.13] G: 0.02 [95% CI: -0.24, 0.28] C: -0.08 [95% CI: -0.22, 0.06]
Pooled effect (random effects model / fixed effects model):
-0.07 [-0.12, -0.02] favoring Haigis
Haigis vs Holladay 1
Mean difference [95% CI]:
I: -0.04 [95% CI: -0.49, 0.41] F: -0.04 [95% CI: -0.13, 0.05] A: -0.12 [95% CI: -0.31, 0.07] J: 0.02 [95% CI: -0.09, 0.13]
Pooled effect (random effects model / fixed effects model):
-0.03 [95% CI: -0.09, 0.04] favoring Haigis
Haigis vs SRK/T
Mean difference [95% CI]:
I: -0.31 [95% CI: -0.81, 0.19] F: -0.07 [95% CI: -0.16, 0.02] A: -0.16 [95% CI: -0.37, 0.05] J: 0.01 [95% CI: -0.10, 0.12] E: -0.16 [95% CI: -0.30, -0.02] C: -0.09 [95% CI: -0.24, 0.06]
Pooled effect (random effects model / fixed effects model):
-0.07 [95% CI: -0.13, -0.02 favoring Haigis
Haigis vs SRK II
Mean difference [95% CI:]:
I: -0.99 [95% CI: -1.55, -0.43] A: -0.37 [95% CI: -0.62, -0.12] E: -0.19 [95% CI: -0.32, -0.06]
Pooled effect (random effects model / fixed effects model):
-0.41 [95% CI: -0.73, -0.09 favoring Haigis |
Facultative:
Brief description of author’s conclusion
Personal remarks on study quality, conclusions, and other issues (potentially) relevant to the research question
Level of evidence: GRADE (per comparison and outcome measure) including reasons for down/upgrading
Sensitivity analyses (excluding small studies; excluding studies with short follow-up; excluding low quality studies; relevant subgroup-analyses); mention only analyses which are of potential importance to the research question
Heterogeneity: clinical and statistical heterogeneity; explained versus unexplained (subgroupanalysis) |
|
Wang, 2018
(long eyes)
[individual study characteristics deduced from [1st author, year of publication ]]
PS., study characteristics and results are extracted from the SR (unless stated otherwise) |
SR and meta-analysis of observational studies
Literature search up to October, 2016
A: Aristodemou, 2011 B: Cooke, 2016 C: Haigis, 2007 D: Kane, 2016 E: Kane, 2017 F: Melles, 2017 G: Roberts, 2017 H: Srivannaboon, 2013 I: Terzi, 2009 J: Wang, 2011 K: Wang, 2013
Study design: RCT [parallel / cross-over], cohort [prospective / retrospective], case-control
Setting and Country:
Source of funding and conflicts of interest: [commercial / non-commercial / industrial co-authorship]
|
Inclusion criteria SR:
(i) focused on individuals with ocular AL longer than 24.5 mm;
(ii) eyes with refractive lens exchange or uncomplicated cataract surgery with in-the-bag fixated IOL implantation;
(iii) used at least two of the selected IOL power calculation formulas (Barrett Universal II, Haigis, Holladay 2, SRK/T, Holladay 1, Hoffer Q); and
(iv) measured AL with IOL-master (partial coherence interferometry, PCI).
Exclusion criteria SR:
(i) included patients with a history of corneal refractive surgery or diseases affecting refraction;
(ii) included toric, multifocal, piggyback or not in-the-bag fixated IOL implantation;
(iii) did not provide MAE data;(iv) did not apply IOL constant optimizations; and
(v) were review articles or discussion papers, conference abstracts or studies done on animals.
11 studies included
Important patient characteristics at baseline: Number of patients; characteristics important to the research question and/or for statistical adjustment (confounding in cohort studies); for example, age, sex, bmi,...
N (patients/eyes), mean age (range)
A: NA/1279, NA yrs B: 54/54, NA yrs C: NA/29, NA yrs D: 449/449, NA yrs E: 387/387, NA yrs F: 1549/1549, NA yrs G: 90/90, NA yrs H: NA/24, NA yrs I: 27/44, 53 ± 7 (38-64) J: 69/94, 62 ± 11 (34-88) K: 75/75, NA
Sex (M/F): A: B: C: D: E: F: G: H: I: J: K:
Groups comparable at baseline?
|
Describe intervention:
A: Hoffer Q B: Barrett Universal II C: Haigis D: Barrett Universal II E: Barrett Universal II F: Barrett Universal II G: Barrett Universal II H: Haigis I: Haigis J: Haigis K: Haigis |
Describe control:
A: Holladay 1; SRK/T B: Haigis; Hoffer Q; Holladay 1; Holladay 2; SRK/T C: Hoffer Q; Holladay 1; SRK/T D: Haigis; Hoffer Q; Holladay 1; Holladay 2; SRK/T E: Holladay 1; SRK/T F: Haigis; Hoffer Q; Holladay 1; Holladay 2; SRK/T G: Hoffer Q; Holladay 2; SRK/T H: Hoffer Q; Holladay 2 I: Hoffer Q; Holladay 2; SRK/T J: Hoffer Q; Holladay 2; SRK/T K: Hoffer Q; Holladay 1; SRK/T |
End-point of follow-up (post-operative refraction):
A: ≥ 4 week B: 3 week to 3 months C: NA D: ≥ 2 weeks E: > 14 days F: 1 monts G: 3-6 weeks H: 3 monts I: 1 mont J: ≥ 3 weeks K: 3 months
|
Barrett Universal II vs Haigis
Mean difference (95% CI:
B: 0.02 [95% CI: -0.12, 0.16] E: -0.07 [95% CI: -0.12, -0.03] F: -0.02 [95% CI: -0.05, 0.01]
Pooled effect (random effects model / fixed effects model):
-0.04 [95% CI: -0.08, 0.01 favoring Barrett Universal II
Barrett Universal II vs Holladay 2
B: -0.10 [95% CI: -0.26, 0.05] D: -0.07 [95% CI: -0.12, -0.03] F: -0.03 [95% CI: -0.06, -0.00] G: -0.02 [95% CI: -0.10, 0.06]
Pooled effect (random effects model / fixed effects model):
-0.04 [95% CI: -0.07, -0.02 favoring Barrett Universal II
Barrett Universal II vs SRK/T
Mean difference [95% CI]:
B: -0.10 [95% CI: -0.25, 0.06] D: -0.07 [95% CI: -0.11, -0.03] E: -0.03 [95% CI: -0.07, 0.02] F: -0.05 [95% CI: -0.09, -0.02] G: -0.03 [95% CI: -0.11, 0.05]
Pooled effect (random effects model / fixed effects model):
-0.05 [95% CI: -0.07, -0.03 favoring Barrett Universal II
Barrett Universal II vs Hoffer Q
Mean difference
B: -0.13 [95% CI: -0.28, 0.03] D: -0.09 [95% CI: -0.14, -0.04] F: -0.06 [95% CI: -0.09, -0.03] G: -0.09 [95% CI: -0.18, -0.00]
Pooled effect (random effects model / fixed effects model):
-0.07 [95% CI: -0.10, -0.05 favoring Barrett Universal II
Barrett Universal II vs Holladay 1
Mean difference
B: -0.19 [95% CI: -0.35, -0.04] D: -0.06 [95% CI: -0.11, -0.01] E: -0.04 [95% CI: -0.09, 0.02] F: -0.08 [95% CI: -0.11, -0.05]
Pooled effect (random effects model / fixed effects model):
-0.07 [95% CI: -0.09, -0.05 favoring Barrett Universal II |
Facultative:
Brief description of author’s conclusion
Personal remarks on study quality, conclusions, and other issues (potentially) relevant to the research question
Level of evidence: GRADE (per comparison and outcome measure) including reasons for down/upgrading
Sensitivity analyses (excluding small studies; excluding studies with short follow-up; excluding low quality studies; relevant subgroup-analyses); mention only analyses which are of potential importance to the research question
Heterogeneity: clinical and statistical heterogeneity; explained versus unexplained (subgroupanalysis) |
|
Study reference |
Study characteristics |
Patient characteristics 2 |
Intervention (I) |
Comparison / control (C) 3
|
Follow-up |
Outcome measures and effect size 4 |
|
Tang, 2020 |
Type of study: Retrospective review
Setting and country:
Division of Ophthalmology, Alpert Medical School, Brown University, Providence 02903, Rhode Island, USA
Funding and conflicts of interest:
None. |
Inclusion criteria: If a patient had cataract surgery in both eyes, we included the eye with the better postoperative best corrected visual acuity (BCVA) in the study as refraction accuracy decreases with worsening BCVA[17]. If both eyes had the same postoperative BCVA, we included the earlier cataract surgery. These inclusion criteria are based on recommendations by Hoffer for optimized study protocol in examining IOL formula accuracy.
Exclusion criteria: Patients were excluded if they had no postoperative refraction within 3wk to 4mo[4,11], AL or lens thickness (LT) not measurable by optical biometry, history of corneal disease, history of refractive surgery, posterior capsular rupture, sulcus IOL, or BCVA worse than 20/40
N total at baseline: 909 AL < 22: N = 16 AL 22-25: N = 762 AL >25: N = 125 |
Describe intervention (treatment/procedure/test):
Barrett Universal II
|
Describe control (treatment/procedure/test):
Holladay 2 |
Length of follow-up: -
Loss-to-follow-up: -
|
< 22 mm AL
MAE (D)
BU II: 0,535
MedAE (D)
BU II: 0,470 Holladay 2: 0,480
ME (D) + SD
BU II: 0,137 + 0,669 Holladay 2: 0,115 + 0,672 |
|
Connell (2019) |
Type of study: Retrospective case review
Setting and country: Private Practice in Melbourne
Funding and conflicts of interest: None. |
Inclusion criteria: patients 18 years and over having uncomplicated conventional or femtosecond laser assisted cataract surgery performed by a single surgeon (BC) at a private operating facility. Capsulotomies were centred on the pupil with implantation of an Acrysof IQ SN60WF (Alcon Laboratories) inserted through a 2.4 mm clear corneal incision.
Exclusion criteria: factors that might impact the postoperative refractive outcome which included: (1) preoperative comorbidities (significant corneal scarring, keratoconus or other ectasia, keratoplasty, past laser vision correction, corneal relaxing incisions), (2) intraoperative complication (anterior or posterior capsule tear, vitreous prolapse or zonular dehiscence), (3) postoperative complications (persistent corneal oedema) or (4) postoperative corrected distance visual acuity worse than 6/12, refraction performed before day 21 postoperatively or incomplete documentation. If both eyes of one patient met the inclusion criteria, one eye was randomly chosen for inclusion.
N total at baseline:846
AL < 22: N = 46 AL 22-26 mm: 774 AL > 26 mm: 44 |
Describe intervention (treatment/procedure/test):
Barrett Universal II Haigis Hoffer Q Holladay 1 Holladay 2 SRK/T
|
Describe control (treatment/procedure/test):
All formules were compared with each other |
Length of follow-up: -
Loss-to-follow-up: -
|
< 22 mm AL
MAE
BU II: 0,479 Haigis:0,472 Hoffer Q: 0,476 Holladay 1: 0,438 Holladay 2: 0,483 SRK/T: 0,475
22-26 mm AL
MAE
BU II: 0,344 Haigis: 0,353 Hoffer Q: 0,368 Holladay 1: 0,343 Holladay 2: 0,350 SRK/T: 0,360
>26 mm AL
MAE
BU II: 0,331 Haigis: 0,322 Hoffer Q: 0,511 Holladay 1: 0,545 Holladay 2: 0,348 SRK/T: 0,407 |
|
Darcy, 2019 |
Type of study: Retrospective case review
Setting and country: two National Health Service (NHS) trusts in the United Kingdom
Funding and conflicts of interest: None. |
Inclusion criteria: uncomplicated phacoemulsification cataract surgery with insertion of one of four different IOL types Alcon SA60AT (Alcon Laboratories, Inc., Fort Worth, TX), Rayner Superflex 920H, Rayner C-Flex 970C (Rayner IOL Ltd., Hove, UK) and Bausch and Lomb Akreos Adapt AO (Bausch and Lomb, Bridgewater, NJ) and pre-operative biometry performed using partial coherence interferometry (IOLMaster, Carl Zeiss Meditec AG, Jena, Germany)
Exclusion criteria: incomplete biometry using the IOLMaster, corneal astigmatism >4.0 dioptres (D), other corneal disease, previous vitrectomy, complicated cataract surgery, post-operative corrected distance visual acuity (CDVA) worse than 20/40 or post-operative complications.
N total at baseline: 10.930
AL < 22: N = 766 AL 22-26 mm: 9527 AL > 26 mm: 637
|
Describe intervention (treatment/procedure/test):
Barrett Universal II Haigis Hoffer Q Holladay 1 Holladay 2 SRK/T
|
Describe control (treatment/procedure/test):
All formules were compared with each other |
Length of follow-up: -
Loss-to-follow-up: -
|
< 22 mm AL
MAE
BU II: 0,493 Haigis:0,486 Hoffer Q: 0,478 Holladay 1: 0,461 Holladay 2: 0,458 SRK/T: 0,492
22-26 mm AL
MAE
BU II: 0,385 Haigis: 0,402 Hoffer Q: 0,401 Holladay 1: 0,387 Holladay 2: 0,387 SRK/T: 0,399
>26 mm AL
MAE
BU II: 0,338 Haigis: 0,359 Hoffer Q: 0,454 Holladay 1: 0,475 Holladay 2: 0,352 SRK/T: 0,363 |
|
Kuthirummal, 2019 |
Type of study: Prospective, observational study
Setting and country:
Funding and conflicts of interest: None. |
Inclusion criteria: Age 40-80 Underwent phacoemulsification
Exclusion criteria: Previous surgeries Intraoperative complications
N total at baseline: 244
AL < 22: N = 53 AL 22-24,5 mm: 135 AL > 24,5 mm: 56 : |
Describe intervention (treatment/procedure/test):
Barrett Universal II
|
Describe control (treatment/procedure/test):
SRK/T
|
Length of follow-up: -
Loss-to-follow-up: -
|
< 22 mm AL
MAE + SD
BU II: 0,35 + 0,28 SRK/T: 0,59 + 0,39
22-24,5 mm AL
MAE + SD
BU II: 0,37 + 0,27 SRK/T: 0,41 + 0,32 |
|
Mustafa, 2019 |
Type of study: Retrospective review
Setting and country:
Funding and conflicts of interest: None. |
Inclusion criteria: having good quality preoperative IOLMaster 5 (Carl Zeiss Meditec, Inc) biometry, where signal-to-noise ratio was 2.0 and above, uneventful phacoemulsification cataract surgery and a postoperative subjective refraction with a best-corrected visual acuity of 6/12 or better for distance.
Exclusion criteria: patient who had undergone previous intraocular or refractive surgery was excluded. Patients with any history of corneal disease were also excluded.
N total at baseline: 84
AL < 22 mm: N = 84 |
Describe intervention (treatment/procedure/test):
Haigis Hoffer Q Holladay 1 SRK/T
|
Describe control (treatment/procedure/test):
All formules were compared with each other |
Length of follow-up: -
Loss-to-follow-up: -
|
< 22 mm AL
MAE + SD
Haigis: 0.76 ± 0.66 Hoffer Q: 0.90 ± 0.68 Holladay 1: 0.74 ± 0.65 SRK/T: 0.75 ± 0.61
|
|
Naeser, 2019 |
Type of study: Rerospective case series
Setting and country: IRCCS GB Bietti Foundation, Rome, Italy
Funding and conflicts of interest: None. |
Inclusion criteria: Consecutive patients having cataract surgery with a monofocal nontoric IOL implanted by the same surgeon (G.S.) were enrolled between January 2014 and January 2018 in a single institution (IRCCS Fondazione GB Bietti, Rome, Italy).
Exclusion criteria: previous intraocular or corneal surgery, any corneal disease including keratoconus, contact lens usage during the previous month, and postoperative corrected distance visual acuity worse than 0.8 (20/25) for any reason. Patients were excluded also when optical biometry measurements were not possible because of lens opacities.
N total at baseline: 151
AL < 22: N = 4 AL 22-26 mm: 131 AL > 26 mm: 16 |
Describe intervention (treatment/procedure/test):
Barrett Universal II Haigis Hoffer Q Holladay1 SRK/T
|
Describe control (treatment/procedure/test):
All formules were compared with each other |
Length of follow-up: -
Loss-to-follow-up: -
|
> 26 mm AL
MAE
BU II: 0,20 Haigis: 0,15 Hoffer Q: 0,29 Holladay 1: 0,45 SRK/T: 0,15
ME + SD
BU II: 0.10 + 0.28 Haigis: -0,02 + 0,24 Hoffer Q: 0,17 + 0,35 Holladay1: 0,41 + 0,38 SRK/T: 0,08 + 0,32
|
|
Savini, 2019 |
Type of study: prospective interventional study
Setting and country:
Funding and conflicts of interest: The contribution of IRCCS - G.B. Bietti Foundation was supported by the Italian Ministry of Health and Fondazione Roma |
Inclusion criteria: patients having cataract surgery and implanted with non-toric, non-multifocal IOLs
Exclusion criteria: prior corneal or intraocular surgery, keratoconus and any other corneal disease, contact lens usage during the previous month and postoperative best corrected visual acuity lower than 0.8 (20/25) for any reason. Patients were excluded also when optical biometry measurements were not possible because of lens opacities (in this case, lens opacities were graded according to the Lens Opacities Classification System III (LOCS))
N total at baseline:151
AL < 22: N = 3 AL 22-24,5 mm: N = 100 AL 24,51-26 mm: N = 29 AL > 26: N = 19
|
Describe intervention (treatment/procedure/test):
Barrett Universal II Haigis Hoffer Q Holladay1 SRK/T
|
Describe control (treatment/procedure/test):
All formules were compared with each other |
Length of follow-up: -
Loss-to-follow-up: -
|
> 26 mm AL
MAE
BU II: 0,253 Haigis:0,298 Hoffer Q: 0,397 Holladay 1: 0,582 Holladay 2: 0,483 SRK/T: 0,312
PE + SD
BU II: -0,011 + 0,323
MedAE BU II: 0,202 |
|
Zhang, 2019 |
Type of study: Retrospective study
Setting and country:
Funding and conflicts of interest: None. |
Inclusion criteria: eyes with AL greater than 26 mm; this biometric measurement was performed using a partial coherence interferometry (PCI) device (IOLMaster 500, Carl Zeiss Meditec, Jena, Germany).
Exclusion criteria: Cases for which parameters were unattainable using PCI were excluded from the study. Eyes that had undergone previous surgery or trauma and those with preexisting ocular diseases that may affect the ability to undertake accurate biometry or refraction (postoperative best-corrected visual acuity less than 20/40) were excluded.
N total at baseline: 108 eyes (94 PT)
|
Describe intervention (treatment/procedure/test):
Barrett Universal II Haigis Hoffer Q Holladay 1 SRK/T
|
Describe control (treatment/procedure/test):
All formulas were compared with each other |
Length of follow-up: -
Loss-to-follow-up: -
|
> 26 mm AL
MAE
BU II: 0,42 Haigis:0,65 Hoffer Q: 0,99 Holladay 1: 0,89 SRK/T: 0,72
ME + SD
MAE
BU II: 0,07 + 0,39 Haigis:0 + 0,51 Hoffer Q: 0 + 0,76 Holladay 1: 0 + 0,65 SRK/T: 0 + 0,56
MedAE
BU II: 0,33 Haigis:0,55 Hoffer Q: 0,85 Holladay 1: 0,78 SRK/T: 0,56 |
|
Roberts, 2018 |
Type of study: Retrospective case series comparison
Setting and country:
Funding and conflicts of interest: None. |
Inclusion criteria: implantation of an AcrySof SN60WF IOL (Alcon, Ft Worth, TX, USA).
Exclusion criteria: previous keratorefractive procedures or pre-existing ocular disease that may have affected the ability to undertake accurate biometry or have resulted in limited visual potential (less than 6/9). Patients with preoperative corneal astigmatism of >0.75 D were excluded from the final cohort. Eyes with corresponding values therefore were excluded from comparison also
N total at baseline: 400
AL < 22: N = 21 AL 22,01-24,5 mm: N = 289
|
Describe intervention (treatment/procedure/test):
Barrett Universal II Hoffer Q SRK/T
|
Describe control (treatment/procedure/test):
All formulas were compared with each other |
Length of follow-up: -
Loss-to-follow-up: -
|
< 22 mm AL
MAE + SD
BU II: 0,43 + 0,36 Hoffer Q: 0,45 + 0,41 SRK/T: 0,44 + 0,41
22,01 – 24,50 mm AL
MAE + SD
BU II: 0,30 + 0,23 Hoffer Q: 0,32 + 0,24 SRK/T: 0,29 + 0,22
|
|
Rong, 2018 |
Type of study: Prospective case serie
Setting and country:
Funding and conflicts of interest: None. |
Inclusion criteria: patients (AL R26.0 mm) with cataract who had uneventful cataract surgery between January 1, 2018, and May 31, 2018, at the Eye and Ear, Nose, and Throat Hospital, Fudan University, were consecutively enrolled.
Exclusion criteria: Patients with glaucoma, strabismus, previous trauma or surgery, zonular fiber weakness, or severe fundus pathology (eg, shallow retinal detachment, choroidal neovascularization, macular hole) were excluded. Patients with a postoperative corrected distance visual acuity (CDVA) worse than 20/40 (ie, 0.3 logarithm of the minimum angle of resolution [logMAR]) were also excluded from the analysis.
N total at baseline: 79
AL 26-28 mm: N = 20 AL 28-30 mm: N = 32 AL > 30 mm: N = 27 |
Describe intervention (treatment/procedure/test):
Barrett Universal II
|
Describe control (treatment/procedure/test):
Haigis
|
Length of follow-up: -
Loss-to-follow-up: -
|
Pooled MAE + SD > 26 mm AL
MAE + SD
BU II: 0,4059 + 0,2586 Haigis: 0,5384 + 0,3709
MedAE
26-28 mm: BU II: 0,37
28-30 mm: BU II: 0,34 Haigis: 0,39
> 30 mm: BU II: 0,40 Haigis: 0,71. |
Tabel Exclusie na het lezen van het volledige artikel
|
Auteur en jaartal |
Redenen van exclusie |
|
Abulafia, 2015 |
Geen uitsplitsing subgroepen |
|
Aristodemou, 2011 |
Geen uitsplitsing subgroepen |
|
Doshi, 2017 |
Geen uitsplitsing subgroepen |
|
Popovic, 2017 |
Geen vergelijking van de door de werkgroep geprioriteerde lenssterkteformules |
|
Ji, 2019 |
Voldoet niet aan uitkomstmaat |
|
Idrobo-Robalino |
Geen uitsplitsing subgroepen |
|
Geggel, 2018 |
Voldoet niet aan uitkomstmaat |
|
Cheng, 2019 |
Geen uitsplitsing subgroepen |
|
Wallace, 2018 |
Geen uitsplitsing resultaten per subgroep |
|
Srivannaboon, 2019 |
Geen uitsplitsing subgroepen en voldoet niet aan uitkomstmaat |
|
Shajari, 2018 |
Geen uitsplitsing subgroepen; voldoet niet aan uitkomstmaat; hele kleine sample size |
|
Sella, 2020 |
Geen uitsplitsing subgroepen; voldoet niet aan uitkomstmaat |
|
Kim, 2019 |
Rapporteert geen resultaten van de subgroepen |
|
Gokce, 2018 |
Geen uitsplitsing subgroepen |
|
Fabian, 2018 |
Geen uitsplitsing subgroepen |
|
Gokce, 2017 |
Geen uitsplitsing subgroepen |
|
Carifi, 2015 |
Studie wordt geïncludeerd in SR van Wang (2018) en niet los geïncludeerd |
|
Cooke, 2016 |
Studie wordt geïncludeerd in SR van Wang (2018) en niet los geïncludeerd |
|
Kane, 2016 |
Studie wordt geïncludeerd in SR van Wang (2018) en niet los geïncludeerd |
|
Melles, 2017 |
Studie wordt geïncludeerd in SR van Wang (2018) en niet los geïncludeerd |
|
Wang, 2010 |
Geen uitsplitsing subgroepen |
|
Wan, 2019 |
Voldoet niet aan uitkomstmaat |
|
Haigis, 2007 |
Studie wordt geëxcludeerd uit SR van Wang (2018) |
|
Kane, 2017 |
Studie wordt geëxcludeerd uit SR van Wang (2018) |
|
Wang, 2011 |
Studie wordt geëxcludeerd uit SR van Wang (2018) |
|
Srivannaboon, 2013 |
Studie wordt geëxcludeerd uit SR van Wang (2018) |
|
Razmjoo, 2017 |
Geen uitsplitsing subgroepen |
Beoordelingsdatum en geldigheid
Publicatiedatum : 15-12-2021
Beoordeeld op geldigheid : 09-11-2021
Algemene gegevens
De ontwikkeling/herziening van deze richtlijnmodule werd ondersteund door het Kennisinstituut van de Federatie Medisch Specialisten en werd gefinancierd uit de Stichting Kwaliteitsgelden Medisch Specialisten (SKMS). De financier heeft geen enkele invloed gehad op de inhoud van de richtlijnmodule.
Doel en doelgroep
Doel
Een richtlijn is in wezen de beschrijving van de actuele stand van de kennis, technieken en gerelateerde zaken rond het onderwerp van de richtlijn. Daarnaast heeft een richtlijn tot doel de beroepsbeoefenaars aanbevelingen te geven die de kwaliteit van hun werk mede op het gewenste niveau kunnen houden. Er is dus ook sprake van een beschrijving van kwalitatieve normen voor de beroepsgroep. Iedere arts is gehouden om primair te handelen in het belang van de patiënten daarbij zorg te dragen voor diens veiligheid in relatie tot het medische handelen. De Richtlijn Cataract stelt dan ook normen vast voor goede praktijkvoering, stelt standaarden voor patiëntenzorg en veiligheid en biedt een referentiepunt voor de beoordeling van de resultaten waaraan cataractchirurgie van hoge kwaliteit moet voldoen. De aanbevelingen, normen en standaarden zijn getoetst aan de resultaten van gedegen wetenschappelijk onderzoek, gepubliceerd in de wetenschappelijke literatuur. Indien zekere vraagstellingen niet goed beantwoord konden worden op basis van literatuuronderzoek, werden de meningen van erkende experts gehoord door de richtlijnwerkgroep en bij consensus verwerkt in de aanbevelingen.
Doelgroep
Deze richtlijn is geschreven voor met name oogartsen maar ook andere leden van de beroepsgroepen die direct betrokken zijn bij de zorg met cataract.
Samenstelling werkgroep
Voor het ontwikkelen van de richtlijnmodule is in 2018 een werkgroep ingesteld, bestaande uit vertegenwoordigers van alle relevante specialismen die betrokken zijn bij de zorg voor patiënten met cataract.
Werkgroep
- Drs. B.A.E. (Bert) van der Pol, oogarts niet praktiserend, (voorzitter) NOG
- Dr. M.C. (Marjolijn) Bartels, oogarts, Deventer Ziekenhuis, NOG
- Drs. M.M.M.J. (Margot) Dellaert, oogarts, Treant Zorggroep, NOG
- Drs. Y.P. (Ype) Henry, oogarts, VU medisch centrum, NOG
- Dr. L.V. (Long) Ly, oogarts, Bergman Clinics, NOG
- Drs. R.C.M. (Marit) Maatman, oogarts, Alrijne Ziekenhuis, NOG
- Dr. N.J. (Nic) Reus, oogarts, Amphia Ziekenhuis, NOG
- Dr. N. (Nienke) Visser, oogarts, Maastricht Universitair Medisch Centrum, NOG
- Prof. Dr. R.M.M.A. (Rudy) Nuijts, oogarts, Maastricht Universitair Medisch Centrum, NOG
Met ondersteuning van
- Dr. A.C.J. (Astrid) Balemans, adviseur, Kennisinstituut van de Federatie Medisch Specialisten
- Dr. J. (Josefien) Buddeke, adviseur, Kennisinstituut van de Federatie Medisch Specialisten
- M. (Mitchel) Griekspoor MSc, junior adviseur, Kennisinstituut van de Federatie Medisch Specialisten
Klankbordgroep
- H.J. (Anneke) Jansen Molenaar, Adviseur Oogzorg bij de Oogvereniging
- D. (Dana) Kamsteeg-Koerts, Optometrist, Oogziekenhuis Rotterdam
Belangenverklaringen
De Code ter voorkoming van oneigenlijke beïnvloeding door belangenverstrengeling is gevolgd. Alle werkgroepleden hebben schriftelijk verklaard of zij in de laatste drie jaar directe financiële belangen (betrekking bij een commercieel bedrijf, persoonlijke financiële belangen, onderzoeksfinanciering) of indirecte belangen (persoonlijke relaties, reputatiemanagement) hebben gehad. Gedurende de ontwikkeling of herziening van een module worden wijzigingen in belangen aan de voorzitter doorgegeven. De belangenverklaring wordt opnieuw bevestigd tijdens de commentaarfase.
Een overzicht van de belangen van werkgroepleden en het oordeel over het omgaan met eventuele belangen vindt u in onderstaande tabel. De ondertekende belangenverklaringen zijn op te vragen bij het secretariaat van het Kennisinstituut van de Federatie Medisch Specialisten.
|
Werkgroeplid |
Functie |
Nevenwerkzaamheden |
Gemelde belangen |
Actie |
|
Van der Pol |
Niet praktiserend |
Geen |
Geen |
Geen actie |
|
Dellaert |
Oogarts |
Medisch manager, onkostenvergoeding |
Geen |
Geen actie |
|
Bartels |
Zelfstandig ondernemer, via B.V. verbonden aan Verenigde Specialisten Deventer en zo aan Deventer Ziekenhuis |
Voorzitter subcommissie Richtlijnen NOG |
Deelname aan ZonMw studie IBSCS / DBSCS via UMC Maastricht (site - investigator)
Contactpersoon namens cornea werkgroep bij hoornvliespatiënten vereniging.
|
Geen trekker van de modules over ontstekings- en infectieprofylaxe bij reguliere cataractchirurgie. |
|
Henry |
Oogarts; staflid
|
Lid van de steering group van EUREQUO (ESCRS); Secretaris van NIOIC (NOG); Voorzitter van WTO (NOG) |
Geen |
Geen actie |
|
Ly |
Oogarts bij Bergman Clinics |
Geen |
Geen |
Geen actie |
|
Maatman |
Oogarts, Alrijne Ziekenhuis
|
NOG bestuur (secretaris), betaald. Tot 2016/2017 advies Bayer / Eylea, betaald
|
Geen |
Geen trekker module ontstekingsprofylaxe reguliere cataractchirurgie. |
|
Reus |
Oogarts in het Amphia Ziekenhuis, Breda/Oosterhout
|
Bestuurslid Nederlandse Intraoculaire Implant Club (NIOIC) (onbetaald) Bestuurslid European Society of Cataract and Refractive Surgeons (ESCRS) (onbetaald)
|
Bestuurslid Nederlandse Intraoculaire Implant Club (NIOIC) (onbetaald)
1.Principal Investigator van Investigator-Initiated Trial waarvoor subsidie van Alcon (unresticted grant). Het onderwerp is de helderheid van ogen na een staaroperatie. Er wordt onderzoek gedaan naar de hoeveelheid lichtverstrooiing in de ogen na een cataractoperatie en redenen waarom er meer strooilicht in het oog overblijft na een cataractoperatie dan wordt verwacht. 2.Site-Investigator van studie naar bilaterale cataractchirurgie geïnitieerd door prof. R. Nuijts, oogarts (Universiteitskliniek voor Oogheelkunde Maastricht) waarvoor subsidie van ZonMW (unresticted grant). |
Geen trekker van modules met betrekking tot infectieprofylaxe bij reguliere cataractchirurgie en IOLs. |
|
Visser |
Oogarts, aandachtsgebieden cornea- en cataract chirurgie. Werkgever: University Eye Clinic Maastricht, MUMC+
|
Young ophthalmology committee ESCRS (onbetaald)
|
EPICAT study: Effectiveness of Periocular drug Injection in CATaract surgery (gefinancierd door ESCRS, het gaat hierbij om een restricted grant, de ESCRS heeft op voorhand akkoord gegeven voor de specifieke opzet, uitvoering, en terugkoppeling van de EPICAT studie) |
Geen actie |
|
Nuijts |
Prof.dr. RMMA Nuijts, hoogleraar Corneatransplantatie en Refractiechirurgie; MUMC Maastricht
|
- Voorzitter Nederlandse IntraOculaire Implant Club, NIOIC (onbetaald) |
Abbott: NL 56878.068.16/METC162029 A randomised, subject-masked evaluation of visual function after bilateral implantation of two types of presbyopia-correcting IOLs: the Symfony-study. Period: 01-12-2016 - 01-12-2018
Alcon: VERION versus conventional, manual ink-marking in toric IOL implantation. Period: 2015 - 2016
Alcon: ILJ466-P003 Post-Market Investigation of the Clareon IOL. Period: 2018 - 2028
Alcon: The ACRYSOF IQ PanOptix Presbyopia Correcting intraocular lens (IOL) Model TFNT00. Period: 01-12-2015 - 01-12-2017
CHIESI: NL 54419.000.15/CCMO15.0538 Multinational, multicentre, prospective, open-label, uncontrolled clinical trial to assess the efficacy and safety of Autologous Cultivated Limbal Stem Cells Transplantation (ACLSCT) for restoration of corneal epithelium in patients with limbal stem cell deficiency due to ocular burns. Period: 01-12-2016 - 01-12-2018
ESCRS: European Cornea and Cell Transplantation Registry (ECCTR), European Union Third Health Programme 2014-2020 and the European Society of Cataract and Refractive Surgeons. Period: 01-04-2016 - 2019
ESCRS: The ESCRS PREMED study: PREvention of Macular EDema after cataract surgery. Period: 2012 - 2016
InSciTE: EyeScite: smart biomedical solutions for better eyesight. |
Geen trekker van de modules met betrekking tot infectie- en onstekingsprofylaxe en IOLs bij reguliere cataractchirurgie. |
|
Kamsteeg-Koerts (klankbordgroep) |
Optometrist, Oogziekenhuis Rotterdam |
- Per 25 november 2019 lid OVN ledenraad met een aanstelling voor 3 jaar - Lid OVN commissie Beroepsbelangen |
Geen
|
Geen actie |
|
Jansen-Molenaar |
Adviseur Oogzorg bij de Oogvereniging |
Geen |
Geen |
Geen actie |
Inbreng patiëntenperspectief
Een afgevaardigde van de Oogvereniging nam zitting in de klankbordgroep. Daarnaast werden de Oogvereniging en de Patiëntenfederatie uitgenodigd om deel te nemen aan de schriftelijke knelpuntenanalyse. De conceptrichtlijn is tevens voor commentaar voorgelegd aan de betrokken patiëntenverenigingen en de eventueel aangeleverde commentaren zijn bekeken en verwerkt.
Methode ontwikkeling
Evidence based
Werkwijze
AGREE
Deze richtlijnmodule is opgesteld conform de eisen vermeld in het rapport Medisch Specialistische Richtlijnen 2.0 van de adviescommissie Richtlijnen van de Raad Kwaliteit. Dit rapport is gebaseerd op het AGREE II instrument (Appraisal of Guidelines for Research & Evaluation II; Brouwers, 2010).
Knelpuntenanalyse en uitgangsvragen
Tijdens de voorbereidende fase inventariseerde de werkgroep de knelpunten in de zorg voor patiënten met cataract. De werkgroep beoordeelde de aanbeveling(en) uit de eerdere richtlijnmodule cataract (2013) op noodzaak tot revisie. Tevens zijn er knelpunten aangedragen door het Nederlands Oogheelkundig Gezelschap (NOG), de Nederlandse Vereniging voor Klinische Geriatrie (NVKG), het Nederlands Huisartsen Genootschap (NHG), de Oogvereniging, Verenso en de Landelijke Vereniging van Operatieassistenten (LVO) via een schriftelijke knelpuntenanalyse. Een verslag hiervan is opgenomen in de bijlagen.
Uitkomstmaten
Na het opstellen van de zoekvraag behorende bij de uitgangsvraag inventariseerde de werkgroep welke uitkomstmaten voor de patiënt relevant zijn. Hierbij werd een maximum van acht uitkomstmaten gehanteerd. De werkgroep waardeerde deze uitkomstmaten volgens hun relatieve belang bij de besluitvorming rondom aanbevelingen, als cruciaal (kritiek voor de besluitvorming) en belangrijk (maar niet cruciaal). Tevens definieerde de werkgroep tenminste voor de cruciale uitkomstmaten welke verschillen zij klinisch (patiënt) relevant vonden.
Methode literatuursamenvatting
Een uitgebreide beschrijving van de strategie voor zoeken en selecteren van literatuur en de beoordeling van de risk-of-bias van de individuele studies is te vinden onder ‘Zoeken en selecteren’ onder Onderbouwing. De beoordeling van de kracht van het wetenschappelijke bewijs wordt hieronder toegelicht.
Beoordelen van de kracht van het wetenschappelijke bewijs
De kracht van het wetenschappelijke bewijs werd bepaald volgens de GRADE-methode. GRADE staat voor ‘Grading Recommendations Assessment, Development and Evaluation’ (zie http://www.gradeworkinggroup.org/). De basisprincipes van de GRADE-methodiek zijn: het benoemen en prioriteren van de klinisch (patiënt) relevante uitkomstmaten, een systematische review per uitkomstmaat en een beoordeling van de bewijskracht per uitkomstmaat op basis van de acht GRADE-domeinen (domeinen voor downgraden: risk of bias, inconsistentie, indirectheid, imprecisie, en publicatiebias; domeinen voor upgraden: dosis-effect relatie, groot effect, en residuele plausibele confounding).
GRADE onderscheidt vier gradaties voor de kwaliteit van het wetenschappelijk bewijs: hoog, redelijk, laag en zeer laag. Deze gradaties verwijzen naar de mate van zekerheid die er bestaat over de literatuurconclusie, in het bijzonder de mate van zekerheid dat de literatuurconclusie de aanbeveling adequaat ondersteunt (Schünemann, 2013; Hultcrantz, 2017).
|
GRADE |
Definitie |
|
Hoog |
|
|
Redelijk |
|
|
Laag |
|
|
Zeer laag |
|
Bij het beoordelen (graderen) van de kracht van het wetenschappelijk bewijs in richtlijnen volgens de GRADE-methodiek spelen grenzen voor klinische besluitvorming een belangrijke rol (Hultcrantz, 2017). Dit zijn de grenzen die bij overschrijding aanleiding zouden geven tot een aanpassing van de aanbeveling. Om de grenzen voor klinische besluitvorming te bepalen moeten alle relevante uitkomstmaten en overwegingen worden meegewogen. De grenzen voor klinische besluitvorming zijn daarmee niet een-op-een vergelijkbaar met het minimale klinisch relevante verschil (Minimal Clinically Important Difference, MCID). Met name in situaties waarin een interventie geen belangrijke nadelen heeft en de kosten relatief laag zijn, kan de grens voor klinische besluitvorming met betrekking tot de effectiviteit van de interventie bij een lagere waarde (dichter bij het nuleffect) liggen dan de MCID (Hultcrantz, 2017).
Overwegingen (van bewijs naar aanbeveling)
Om te komen tot een aanbeveling zijn naast (de kwaliteit van) het wetenschappelijke bewijs ook andere aspecten belangrijk en worden die meegewogen, zoals aanvullende argumenten uit bijvoorbeeld de biomechanica of fysiologie, waarden en voorkeuren van patiënten, kosten (middelenbeslag), aanvaardbaarheid, haalbaarheid en implementatie. Deze aspecten zijn systematisch vermeld en beoordeeld (gewogen) onder het kopje ‘Overwegingen’ en kunnen (mede) gebaseerd zijn op expert opinion. Hierbij is gebruik gemaakt van een gestructureerd format gebaseerd op het evidence-to-decision framework van de internationale GRADE Working Group (Alonso-Coello, 2016a; Alonso-Coello, 2016b). Dit evidence-to-decision framework is een integraal onderdeel van de GRADE methodiek.
Formuleren van aanbevelingen
De aanbevelingen geven antwoord op de uitgangsvraag en zijn gebaseerd op het beschikbare wetenschappelijke bewijs, de belangrijkste overwegingen en een weging van de gunstige en ongunstige effecten van de relevante interventies. De kracht van het wetenschappelijk bewijs en het gewicht dat door de werkgroep wordt toegekend aan de overwegingen bepalen samen de sterkte van de aanbeveling. Conform de GRADE-methodiek sluit een lage bewijskracht van conclusies in de systematische literatuuranalyse een sterke aanbeveling niet a priori uit en zijn bij een hoge bewijskracht ook zwakke aanbevelingen mogelijk (Agoritsas, 2017; Neumann, 2016). De sterkte van de aanbeveling wordt altijd bepaald door weging van alle relevante argumenten tezamen. De werkgroep heeft bij elke aanbeveling opgenomen hoe zij tot de richting en sterkte van de aanbeveling zijn gekomen.
In de GRADE-methodiek wordt onderscheid gemaakt tussen sterke en zwakke (of conditionele) aanbevelingen. De sterkte van een aanbeveling verwijst naar de mate van zekerheid dat de voordelen van de interventie opwegen tegen de nadelen (of vice versa), gezien over het hele spectrum van patiënten waarvoor de aanbeveling is bedoeld. De sterkte van een aanbeveling heeft duidelijke implicaties voor patiënten, behandelaars en beleidsmakers (zie onderstaande tabel). Een aanbeveling is geen dictaat, zelfs een sterke aanbeveling gebaseerd op bewijs van hoge kwaliteit (GRADE-gradering HOOG) zal niet altijd van toepassing zijn onder alle mogelijke omstandigheden en voor elke individuele patiënt.
|
Implicaties van sterke en zwakke aanbevelingen voor verschillende richtlijngebruikers |
||
|
|
Sterke aanbeveling |
Zwakke (conditionele) aanbeveling |
|
Voor patiënten |
De meeste patiënten zouden de aanbevolen interventie of aanpak kiezen en slechts een klein aantal niet. |
Een aanzienlijk deel van de patiënten zouden de aanbevolen interventie of aanpak kiezen, maar veel patiënten ook niet. |
|
Voor behandelaars |
De meeste patiënten zouden de aanbevolen interventie of aanpak moeten ontvangen. |
Er zijn meerdere geschikte interventies of aanpakken. De patiënt moet worden ondersteund bij de keuze voor de interventie of aanpak die het beste aansluit bij zijn of haar waarden en voorkeuren. |
|
Voor beleidsmakers |
De aanbevolen interventie of aanpak kan worden gezien als standaardbeleid. |
Beleidsbepaling vereist uitvoerige discussie met betrokkenheid van veel stakeholders. Er is een grotere kans op lokale beleidsverschillen. |
Organisatie van zorg
In de knelpuntenanalyse en bij de ontwikkeling van de richtlijnmodule is expliciet aandacht geweest voor de organisatie van zorg: alle aspecten die randvoorwaardelijk zijn voor het verlenen van zorg (zoals coördinatie, communicatie, (financiële) middelen, mankracht en infrastructuur). Randvoorwaarden die relevant zijn voor het beantwoorden van deze specifieke uitgangsvraag zijn genoemd bij de overwegingen. Meer algemene, overkoepelende, of bijkomende aspecten van de organisatie van zorg worden behandeld in de module Organisatie van zorg.
Commentaar- en autorisatiefase
De conceptrichtlijnmodule werd aan de betrokken (wetenschappelijke) verenigingen en (patiënt) organisaties voorgelegd ter commentaar. De commentaren werden verzameld en besproken met de werkgroep. Naar aanleiding van de commentaren werd de conceptrichtlijnmodule aangepast en definitief vastgesteld door de werkgroep. De definitieve richtlijnmodule werd aan de deelnemende (wetenschappelijke) verenigingen en (patiënt) organisaties voorgelegd voor autorisatie en door hen geautoriseerd dan wel geaccordeerd.
Literatuur
Agoritsas T, Merglen A, Heen AF, Kristiansen A, Neumann I, Brito JP, Brignardello-Petersen R, Alexander PE, Rind DM, Vandvik PO, Guyatt GH. UpToDate adherence to GRADE criteria for strong recommendations: an analytical survey. BMJ Open. 2017 Nov 16;7(11):e018593. doi: 10.1136/bmjopen-2017-018593. PubMed PMID: 29150475; PubMed Central PMCID: PMC5701989.
Alonso-Coello P, Schünemann HJ, Moberg J, Brignardello-Petersen R, Akl EA, Davoli M, Treweek S, Mustafa RA, Rada G, Rosenbaum S, Morelli A, Guyatt GH, Oxman AD; GRADE Working Group. GRADE Evidence to Decision (EtD) frameworks: a systematic and transparent approach to making well informed healthcare choices. 1: Introduction. BMJ. 2016 Jun 28;353:i2016. doi: 10.1136/bmj.i2016. PubMed PMID: 27353417.
Alonso-Coello P, Oxman AD, Moberg J, Brignardello-Petersen R, Akl EA, Davoli M, Treweek S, Mustafa RA, Vandvik PO, Meerpohl J, Guyatt GH, Schünemann HJ; GRADE Working Group. GRADE Evidence to Decision (EtD) frameworks: a systematic and transparent approach to making well informed healthcare choices. 2: Clinical practice guidelines. BMJ. 2016 Jun 30;353:i2089. doi: 10.1136/bmj.i2089. PubMed PMID: 27365494.
Brouwers MC, Kho ME, Browman GP, Burgers JS, Cluzeau F, Feder G, Fervers B, Graham ID, Grimshaw J, Hanna SE, Littlejohns P, Makarski J, Zitzelsberger L; AGREE Next Steps Consortium. AGREE II: advancing guideline development, reporting and evaluation in health care. CMAJ. 2010 Dec 14;182(18):E839-42. doi: 10.1503/cmaj.090449. Epub 2010 Jul 5. Review. PubMed PMID: 20603348; PubMed Central PMCID: PMC3001530.
Hultcrantz M, Rind D, Akl EA, Treweek S, Mustafa RA, Iorio A, Alper BS, Meerpohl JJ, Murad MH, Ansari MT, Katikireddi SV, Östlund P, Tranæus S, Christensen R, Gartlehner G, Brozek J, Izcovich A, Schünemann H, Guyatt G. The GRADE Working Group clarifies the construct of certainty of evidence. J Clin Epidemiol. 2017 Jul;87:4-13. doi: 10.1016/j.jclinepi.2017.05.006. Epub 2017 May 18. PubMed PMID: 28529184; PubMed Central PMCID: PMC6542664.
Medisch Specialistische Richtlijnen 2.0 (2012). Adviescommissie Richtlijnen van de Raad Kwalitieit. https://richtlijnendatabase.nl/over_deze_site.html
Neumann I, Santesso N, Akl EA, Rind DM, Vandvik PO, Alonso-Coello P, Agoritsas T, Mustafa RA, Alexander PE, Schünemann H, Guyatt GH. A guide for health professionals to interpret and use recommendations in guidelines developed with the GRADE approach. J Clin Epidemiol. 2016 Apr;72:45-55. doi: 10.1016/j.jclinepi.2015.11.017. Epub 2016 Jan 6. Review. PubMed PMID: 26772609.
Schünemann H, Brożek J, Guyatt G, et al. GRADE handbook for grading quality of evidence and strength of recommendations. Updated October 2013. The GRADE Working Group, 2013. Available from http://gdt.guidelinedevelopment.org/central_prod/_design/client/handbook/handbook.html.
Zoekverantwoording
Algemene informatie
|
Richtlijn: Cataract |
|
|
Uitgangsvraag: Welke formule(s) voor het berekenen van de lenssterkte heeft/hebben de voorkeur door de komst van nieuwe lensformules? |
|
|
Database(s): Medline, Embase |
Datum: 5-3-2020 |
|
Periode: 2010 – maart 2020 |
Talen: Engels |
|
Literatuurspecialist: Miriam van der Maten |
|
|
Toelichting en opmerkingen: Voor deze search is gezocht op de P en I van de PICO. De subgroep patiënten met cataract + patients after myopic/hyperopic laser refractive surgery wordt ook gevangen in de search. In afstemming met de adviseur is er voor gekozen om voor de observationele studies ook te zoeken met de uitkomstmaat 'prediction error(s)' om de hoeveelheid ruis te beperken. De drie sleutelartikelen van Gökce (2018), Gökce (2017) en Abulafia (2015) worden gevonden met de zoekopdracht. De subgroep sleutelartikelen van Wang (2019), Vrijman (2019), Abulafia (2016), Chen (2016) en McCarthy (2011) worden ook gevonden met de zoekopdracht. |
|
Zoekopbrengst
|
|
EMBASE |
OVID/MEDLINE |
Ontdubbeld |
|
SRs |
7 |
27 |
29 |
|
RCTs |
138 |
129 |
219 |
|
Observationele studies |
91 |
140 |
137 |
|
Totaal |
236 |
296 |
385 |
|
Database |
Zoektermen |
||||||||||||||||||||||||||||||||||||||||||
|
Embase |
|
||||||||||||||||||||||||||||||||||||||||||
|
Medline |
1 exp Cataract/ or cataract*.ti,ab,kf. or (lens* adj2 (opacit* or clouding)).ti,ab,kf. or ('posterior capsule' adj2 opacification).ti,ab,kf. (63232) 2 exp Refractive Surgical Procedures/ or (refractive adj3 (surgery or surgical)).ti,ab. or exp Axial Length, Eye/ or 'axi* length'.ti,ab,kf. (66225) 3 ((exp Lenses, Intraocular/ or exp Lens Implantation, Intraocular/) and (formula* or calculat*).ti,ab,kf.) or (('intraocular lens' or iol) adj2 (formula* or calculat*)).ti,ab,kf. or holladay*.ti,ab,kf. or "srk/t".ti,ab,kf. or hoffer*.ti,ab,kf. or haigis*.ti,ab,kf. or barret.ti,ab,kf. or 'hill-rbf'.ti,ab,kf. or shammas.ti,ab,kf. or masket.ti,ab,kf. or 'history method'.ti,ab,kf. or 'ASCRS calculator'.ti,ab,kf. (3020) 4 1 or 2 (102722) 5 3 and 4 (2038) 6 limit 5 to (english language and yr="2010 -Current") (959) 7 (meta-analysis/ or meta-analysis as topic/ or (meta adj analy$).tw. or ((systematic* or literature) adj2 review$1).tw. or (systematic adj overview$1).tw. or exp "Review Literature as Topic"/ or cochrane.ab. or cochrane.jw. or embase.ab. or medline.ab. or (psychlit or psyclit).ab. or (cinahl or cinhal).ab. or cancerlit.ab. or ((selection criteria or data extraction).ab. and "review"/)) not (Comment/ or Editorial/ or Letter/ or (animals/ not humans/)) (433858) 8 (exp clinical trial/ or randomized controlled trial/ or exp clinical trials as topic/ or randomized controlled trials as topic/ or Random Allocation/ or Double-Blind Method/ or Single-Blind Method/ or (clinical trial, phase i or clinical trial, phase ii or clinical trial, phase iii or clinical trial, phase iv or controlled clinical trial or randomized controlled trial or multicenter study or clinical trial).pt. or random*.ti,ab. or (clinic* adj trial*).tw. or ((singl* or doubl* or treb* or tripl*) adj (blind$3 or mask$3)).tw. or Placebos/ or placebo*.tw.) not (animals/ not humans/) (1952535) 9 Epidemiologic studies/ or case control studies/ or exp cohort studies/ or Controlled Before-After Studies/ or Case control.tw. or (cohort adj (study or studies)).tw. or Cohort analy$.tw. or (Follow up adj (study or studies)).tw. or (observational adj (study or studies)).tw. or Longitudinal.tw. or Retrospective*.tw. or prospective*.tw. or consecutive*.tw. or Cross sectional.tw. or Cross-sectional studies/ or historically controlled study/ or interrupted time series analysis/ [Onder exp cohort studies vallen ook longitudinale, prospectieve en retrospectieve studies] (3374940) 10 6 and 7 (27) 11 (6 and 8) not 10 (129) 12 (6 and 9) not (10 or 11) (529) 13 10 or 11 or 12 (685) 14 "prediction error*".ti,ab,kf. (5790) 15 12 and 14 (140) |